【2024年版】C#でUTAUプラグイン開発を始める方法
はじめに
2019年ごろに初心者支援で作成したC#向けクラスライブラリ「UtauPlugin」が今もご利用いただけています。
当時作成したチュートリアルが現状に合わない部分も出てきました。
更に、チュートリアルまではできたけどその次どうすればいいかわからないという問題も出てきました。
そこであらためて、導入記事を作成するものです。
「選択したノートをすべて半音上げるプラグイン」までお読みいただければ、従来のチュートリアル程度の内容になっております。
前提
Microsoft Visual Studio Community 2022がインストール済みとします。
まだの方はMicrosoft公式を参考にインストールしてください。
なお、手順4,5において.Net Framework 4.8関連の物をインストールしておいてください。
新しいプロジェクトの作成
visual studioを起動し、[新しいプロジェクトの作成]を選びます。

C# の コンソールアプリ(.Net Framework)を選択します。

半角英数字でプロジェクト名を付けます。
名前は何でも構いませんが、以降ここでつけたプロジェクト名を使います。

プロジェクトにUtauPluginを読み込む
[参照]を右クリックし、[NuGetパッケージの管理]を選びます。

[参照]タブに移動し、検索窓に[kimigatame]と入力します。 表示された[Kimigatame.UtauPlugin]をインストールします。

[適用]をクリックします。

導入できました。

選択したノートを1つの音程を C#4にするプラグイン
1.Program.csを以下のように編集します。
using UtauPlugin;
namespace UtauPluginTutorial1
{
internal class Program
{
static void Main(string[] args)
{
int targetNoteNum = 61;
UtauPlugin.UtauPlugin utauPlugin = new UtauPlugin.UtauPlugin(args[0]);
utauPlugin.Input();
utauPlugin.note[1].SetNoteNum(targetNoteNum);
utauPlugin.Output();
}
}
}
2.[ビルド]から[ソリューションのビルド]を選択します。

3.UtauPluginTutorial1\UtauPluginTutorial1\bin\Debugを開き、plugin.txtを作成します。

name=UtauPluginTutorial1 execute=UtauPluginTutorial1.exe
ここで、nameは好きな名前で結構です。
executeは今回のプロジェクト名.exeにします。

4.UtauPluginTutorial1\UtauPluginTutorial1\bin\DebugをUTAUのpluginsフォルダにコピーし、フォルダ名を適当に変更します。

5.今回作成したプラグインを使ってみます。2つ以上ノートを選択してプラグインを実行すると、1つだけC#4になりました。


選択したノートを1つの音程を C#4にするプラグインの解説
先ほどのコードを見ていきます。
using UtauPlugin;
C#では、他の人が作った機能やwindowsの標準機能を使うときにusing 使いたい機能;を冒頭に書いて宣言します。
これはNuGetから取得したUtauPluginを使いますよという意味になります。
namespace UtauPluginTutorial1
{
internal class Program
{
static void Main(string[] args)
{
}
}
}
ここの部分は初心者に説明するのが若干難しいので、こういうものだと思っておいてください。
int targetNoteNum = 61;
プログラムの世界では、値を覚えておく箱のようなものを 変数と呼びます。
C#では、変数の型 変数の名前 = 変数の値という形で変数を宣言します。
変数の型とは種類のようなものだと思ってください。
intとはもともとC#が持っている変数の型の1つで、整数を扱います。
UtauPlugin.UtauPlugin utauPlugin = new UtauPlugin.UtauPlugin(args[0]);
ここでも変数を宣言しています。
若干複雑なので最初のうちはUtauPluginを初期化するための定型文だと思っておいてください。
utauPluginという名前のUtauPlugin.UtauPluginという型の変数を宣言しています。
値はnew UtauPlugin.UtauPlugin(args[0])です。
utauPlugin.Input()
C#では何らかの機能を持つ一連の処理を メソッド と呼び、メソッド名()のような形で使います。
utauPlugin.Input()はUTAUからもらったデータを読み込むためのメソッドです。
utauPlugin.note[1].SetNoteNum(targetNoteNum);
メソッドには、値を指定して処理を実行するものがあります。
この時メソッドに渡す値のことを引数とよび、メソッド名(引数)のような形で使います。
引数がどのような値を受け取るかはメソッド毎に決まっており、note[1].SetNoteNum()はint型の値を受け取ります。
note[1].SetNoteNum(引数)はnote[1]のNotenum(音程)を引数の値に変更する処理です。
今回は予め宣言しているint型の変数targetNoteNumを用い、note[1].SetNoteNum(targetNoteNum)としました。
変数を使わずにnote[1].setNoteNum(61)のように直接数値を指定することもできます。
utauPlugin.Output()
utauPlugin.Output()はプラグインの処理の結果を確定し、UTAUに返すためのファイルを出力する処理です。
選択したノートを1つの音程を半音上げるプラグイン
Program.csを以下のように編集します。
using UtauPlugin;
namespace UtauPluginTutorial1
{
internal class Program
{
static void Main(string[] args)
{
int targetNoteNum = utauPlugin.note[1].GetNoteNum() + 1;
UtauPlugin.UtauPlugin utauPlugin = new UtauPlugin.UtauPlugin(args[0]);
utauPlugin.Input();
utauPlugin.note[1].SetNoteNum(targetNoteNum);
utauPlugin.Output();
}
}
}
最初のコードと異なる部分は
int targetNoteNum = utauPlugin.note[1].GetNoteNum() + 1;です。
メソッドの中には何らかの処理をした後、その結果を返すものがあります。
メソッドから帰ってくる値のことを戻り値と呼びます。
メソッドがどのような型の戻り値を返すかはメソッド毎に決まっております。
note[1].GetNoteNumはnote[1]の現在の音高番号を返すメソッドです。
note[1].SetNoteNum(note[1].GetNoteNum()+1);のように、戻り値を直接他のメソッドの引数にすることもできます。
選択したノートをすべて半音上げるプラグイン
同じ型の変数をたくさん作ったり一括で処理したいとき、C#ではListが便利です。
aという名前のリストがあったとすると、a[0],a[1],a[2]のようにそれぞれの要素にアクセスできます。
また、以下のように記述することで、全ての要素に一括で処理することができます。
foreach(型名 新しい変数名 in リスト名){
新しい変数名に何らかの処理
}
utauPlugin.notesはUtauPlugin.Note型のリストです。
foreachを使ってすべてのノートを半音上げる処理は以下のようになります。
using UtauPlugin;
namespace UtauPluginTutorial1
{
internal class Program
{
static void Main(string[] args)
{
UtauPlugin.UtauPlugin utauPlugin = new UtauPlugin.UtauPlugin(args[0]);
utauPlugin.Input();
foreach(Note note in utauPlugin.note){
note.SetNoteNum(note.GetNoteNum() + 1);
}
utauPlugin.Output();
}
}
}
特定の音程のノートを半音上げるプラグイン
次は特定の条件でだけ値を変更するプラグインを考えます。
C#では特定の条件のときだけ処理する際に、以下のように記述します。
if(条件式){
条件式に当てはまる場合の処理
}
条件式には以下のような例があります。
| 記述 | 意味 |
|---|---|
a==b |
aとbが等しい場合 |
a!=b |
aとbが等しくない場合 |
a>=b |
aがb以上の場合 |
a>b |
aがb超過の場合 |
a<=b |
aがb以下の場合 |
a<b |
aがb未満の場合 |
a>=b && a<c |
aがb以上 かつ aがc未満の場合 |
a>=b && a<c |
aがb以上 もしくは aがc未満の場合 |
音高がC4(60)未満のとき半音を上げるプラグインは下記のようになります。
using UtauPlugin;
namespace UtauPluginTutorial1
{
internal class Program
{
static void Main(string[] args)
{
UtauPlugin.UtauPlugin utauPlugin = new UtauPlugin.UtauPlugin(args[0]);
utauPlugin.Input();
foreach(Note note in utauPlugin.note){
if(note.GetNoteNum() < 60) {
note.SetNoteNum(note.GetNoteNum() + 1);
}
}
utauPlugin.Output();
}
}
}
条件に当てはまるときとそうではないときで異なる処理をするプラグイン
C#では最初の条件に当てはまらなかった際に逐次条件に当てはまるか確認する際は以下のように記述します。
if(最初の条件式){
最初の条件式に当てはまる場合の処理
}else if(2つめの条件式){
最初の条件式にあてはまらず、2つ目の条件式に当てはまる場合の処理
}else if(3つめの条件式{
最初の条件式と2つ目の条件式に当てはまらず、3つ目の条件式に当てはまる場合の処理
}else{
すべての条件式に当てはまらない場合の処理
}
else ifの数は増やしても減らしても構いません。
また、elseは無くても構いません。
音高がC4(60)未満のとき半音を上げ、C4丁度の時は半音下げ、どちらにも当てはまらない場合1オクターブ上げるプラグインは下記のようになります。
using UtauPlugin;
namespace UtauPluginTutorial1
{
internal class Program
{
static void Main(string[] args)
{
UtauPlugin.UtauPlugin utauPlugin = new UtauPlugin.UtauPlugin(args[0]);
utauPlugin.Input();
foreach(Note note in utauPlugin.note){
if(note.GetNoteNum() < 60) {
note.SetNoteNum(note.GetNoteNum() + 1);
}else if(note.GetNoteNum() == 60){
note.SetNoteNum(note.GetNoteNum() - 1);
}else{
note.SetNoteNum(note.GetNoteNum() + 12);
}
}
utauPlugin.Output();
}
}
}
単独音・連続音を考慮して特定の歌詞の時音量を上げるプラグイン
歌詞が[い]の時だけ音量を半分にしたいとします。
一口に[い]といっても、単独音・連続音を考慮すると、以下のように8種類あります。
単独音:[い]、連続音[- い][a い][i い][u い][e い][o い][n い]
if(note.lyric=="い" || note.lyric=="- い" || note.lyric=="a い" || note.lyric=="i い" || note.lyric=="u い" || note.lyric=="e い" || note.lyric=="o い" || note.lyric=="n い")でも間違いではありませんが冗長です。
C#では、以下のように文字列の後方一致を条件にすることができます。
if(一致するか調べたい文字列.EndsWith(検索値))
参考までに前方一致を条件にしたい場合
if(一致するか調べたい文字列.StartsWith(検索値))
となります。
歌詞が[い]の時だけ音量を半分にするコードは以下の通りとなります。
using UtauPlugin;
namespace UtauPluginTutorial1
{
internal class Program
{
static void Main(string[] args)
{
UtauPlugin.UtauPlugin utauPlugin = new UtauPlugin.UtauPlugin(args[0]);
utauPlugin.Input();
foreach(Note note in utauPlugin.note){
if(note.GetLyric().EndsWith("い")) {
note.SetIntensity(note.GetIntensity() / 2);
}
}
utauPlugin.Output();
}
}
}
表情音源を考慮して特定の歌詞の時音量を上げるプラグイン
[- い][a い強][i い弱]のような音源があったとします。
末尾の表情音源まで考慮に入れると、EndsWithを使ってもうまく条件を設定することができません。
正規表現を使うと、複雑な文字列が条件に一致するか調べたり、条件に一致する文字列を抽出することができます。
以下は正規表現の一例です。
| 記述方法 | 意味 |
|---|---|
(a|i|u|e|o|n) |
aiueonのいずれか1文字 |
^(a|i|u|e|o|n) |
aiueonのいずれか1文字から始まる |
(a|i|u|e|o|n)$ |
aiueonのいずれかで終わる |
a? |
0文字か1文字のa |
a* |
0文字以上連続するのa |
a+ |
1文字以上連続するa |
a(3) |
3回連続するa |
a(0-3) |
0~3回連続するa |
[aiueon]* |
0文字以上連続するaiueon |
[a-z] |
半角小文字アルファベット |
[A-Z] |
半角大文字アルファベット |
[0-9] |
半角数字 |
[^a-z] |
半角小文字アルファベット以外 |
^[-aiueon]? ?[あ-んヴ][ゃゅょぁぃぇぉ]? |
日本語の単独音もしくは連続音に前方一致 |
正規表現を用い、表情音源部分を無視して、単独音・連続音問わず「い」の音量を半分にするプラグインは下記の通りになります。
using System.Text.RegularExpressions;
using UtauPlugin;
namespace UtauPluginTutorial1
{
internal class Program
{
static void Main(string[] args)
{
UtauPlugin.UtauPlugin utauPlugin = new UtauPlugin.UtauPlugin(args[0]);
utauPlugin.Input();
foreach(Note note in utauPlugin.note){
if(Regex.IsMatch(note.GetLyric(),@"^[-aiueon]? ?い")) {
note.SetIntensity(note.GetIntensity() / 2);
}
}
utauPlugin.Output();
}
}
}
正規表現を用いるためにはusing System.Text.RegularExpressions;を記述します。
また、正規表現のパターンは@"パターン"のように@とダブルクオーテーションで記述します。
.Net8でUtauPluginを使用する場合
そのままではShift_JISを使用する部分でエラーが生じるため、Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);を追加する。
選択範囲全体を半音上げるプラグインの場合下記の通り
using System.Text;
using UtauPlugin;
UtauPlugin.UtauPlugin utauPlugin = new UtauPlugin.UtauPlugin(args[0]);
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
utauPlugin.Input(false);
foreach (Note note in utauPlugin.note)
{
note.SetNoteNum(note.GetNoteNum() + 1);
}
utauPlugin.Output();
【UTAU講座】ニコニコ動画にUTAUの動画を投稿するときのタグのつけ方
▽ はじめに
ニコニコ動画の魅力を1つ挙げるなら、好きなジャンルの動画を的確に探せる 「タグ検索機能」 でしょう。 特定のジャンルの動画を追いかけている人は日々タグ検索をしているはずです。
自身の動画をタグ検索で見つけてもらうためにも、適切なタグを設定することは極めて重要です。 この記事では、ニコニコ動画にUTAU動画を投稿する際のタグの付け方を解説します。
▽ ニコニコ動画のタグ検索の仕様
ニコニコ動画のタグ検索は 「完全一致検索」 です。
例えば、「UTAU」と検索したとすると、
ヒットする
「UTAU」「utau」「Utau」
ヒットしない
「UTAUオリジナル曲」「UTAUカバー曲」「UTAU音源配布所リンク」
のようになります。
つまり、 みんなが使い、みんなが検索するタグと一字一句同じタグを付ける ことが重要です。
▽ UTAU動画全般に付けるタグ
UTAU
基本的には全てのUTAU動画に付けましょう。
[音源名のタグ]
具体例
「重音テト」「波音リツ」「仄歌エリー」「花撫シア」
音源名が短かったり一般名詞だったりする場合
名前の後ろに「(UTAU)」を付けて検索結果が混ざらないようにします。
「ルーク(UTAU)」「kye(UTAU)」「匿名(UTAU) 」
音源名に半角スペースが含まれる場合
半角スペースの代わりに「_」(アンダーバー)を使います。
「number_bronze」
よく分からないとき
他の音源配布動画を見てタグをまねしましょう。
▽ 音源配布動画に付けるタグ
UTAU音源配布所リンク
新しく録音した音源をお披露目するときに使いましょう。
動画説明文に音源のダウンロードリンクや、音源配布サイトのリンクを配置してください。
なお、仮に音源配布サイトのリンクを配置していても、、既にニコニコ動画でお披露目している音源には使わないことを推奨します。
例外的に、1~数日にかけて複数の音源配布動画を投稿する企画で、そのいずれもがその音源のお披露目動画といえる状況なら付けても大丈夫です。
▽ 配布準備中の自音源動画に付けるタグ
UTAU音源テスト
こちらのタグは何度でも使ってOK
▽ 主にカバー動画で使うタグ
曲名タグ
原作の動画を参考に曲名のタグを付けましょう。
原作に曲名タグが付いていない場合は、先に投稿されている歌ってみた動画やカバー動画をまねしましょう。
曲名のみのパターン
「好きな惣菜発表ドラゴン」「熱異常」「人マニア」
曲名 + 作者名のパターン
「オーバーライド(吉田夜世)」
UTAUカバー曲
最近よく使われるタグです。
VOCALOID→UTAUカバー曲
昔からよく使われているタグですが、最近は原作がVOCALOIDではないことも増えてきたので、付けなくても大丈夫です。
cevio→UTAUカバー曲、 UTAU→UTAUカバー曲、NNI→UTAUカバー曲、synthv→UTAUカバー曲などもありますが、正直あまり使われていません。
▽ オリジナル曲に付けるタグ
UTAUオリジナル曲
よく使われるタグです。
「テトオリジナル曲」など
たくさんオリジナル曲が投稿されている音源では使う場合があります。
UTAU新曲リンク
自身の最新のオリジナル曲1曲のみに付けることがいいとされているタグです。
新しい曲を投稿したら外します。
曲名タグ
カバーや二次創作を歓迎する場合、付けていただけると大変助かります。
既に使われているタグと曲名が被る場合、「曲名(作者名)」の形にします
▽ その他UTAU関係の動画タグ
HANASU
UTAUをトークソフトのように使って喋らせたときに使います。
UTAUと話声合成ソフトの両方の音源があるキャラクターを話声合成ソフトで喋らせたときには使いません。
ODORU
UTAUのキャラクターでMMDの動画をアップするときに使います。
実際に踊っていなくても、MMDの動画であれば付けていいとされています。
調声晒し
曲にあわせてUTAUの操作画面を表示する動画に使います。
ust配布
その名の通りustを配布する場合に使います。
ustの配布は、比較的権利関係を真面目にやってる近代UTAU界隈の中ではかなり権利的に怪しい行動です。
原作者に怒られたらしっかりごめんなさいをするなど自己責任で。
UTAUプラグイン配布あり
UTAUプラグインを配布する際に使います。
UTAUイベント告知動画
UTAUの投稿祭などを企画する際に使います。
自音源の誕生祭などを事前に告知する場合もこちらを活用してください。
▽ 誰かに付けてもらえるとうれしいけど自分で付けないタグ
ニコニコ動画では、タグロックしていないタグなら視聴者も編集できるため、高評価を意味するタグを付けてくれる場合があります。
自分ではつけずに、誰かが設定してくれたら嬉しい、そんなタグです。
良調教
歌わせるのが上手だった場合、視聴者が付けてくれることがあります。
神調教
ものすごく歌わせるのが上手だった場合、視聴者が付けてくれることがあります。
もっと評価されるべき
作品のクオリティーが高かったとき、視聴者が付けてくれることがあります。
期待の新音源
UTAU音源配布所動画において、クオリティーが高かった場合に視聴者が付けてくれることがあります。
UTAUユーザーのためのblenderでMMDモデル作る(9.目を作る)
目次
この記事でやること
- 複製[shift]+[d]
- オブジェクトの分離[p]
- マテリアルの分離
- カーソルの移動
- ピポットポイント
- 同一直線選択[alt]+クリック
- 数量指定
- プロポーショナル変形 [o]
- ラティスモディファイア
- 回転[r]
眼の作り方はいろいろあるようですが、深くくぼんだ白目の上に円盤を加工して瞳を作っていきます。
眼の縁を複製して白目を作る
まず、眼の縁より1週外側をすべて選択します。
[shift]+[d]を押すと複製され、移動モードになります。
位置がずれないように、そのまま[enter]で確定します。
[p]を押して分離メニューを開き、[選択]をクリックします。
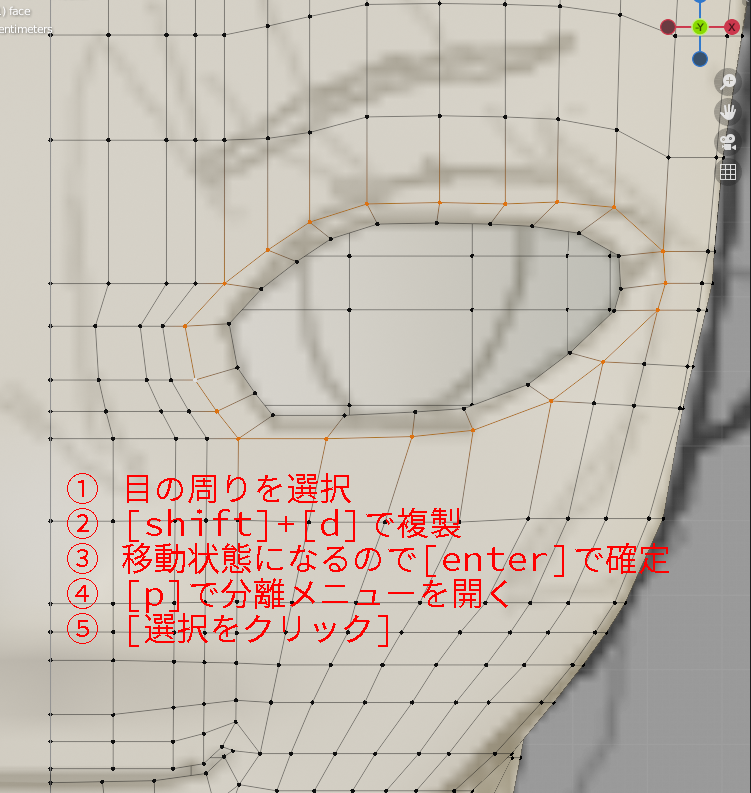
複製されました。一度オブジェクトモードに戻り、複製された[face.001]を選択して再び[編集モード]に入ります

[a]で全体を選択し、[e][y]で2段階奥に出します。
最後に作った奥の頂点を全て選択している状態で、[m]のマージメニューを開き[中心]で結合します。

シェーディングをスムーズにしておきます。
適当に白目を奥に移動させておきます。
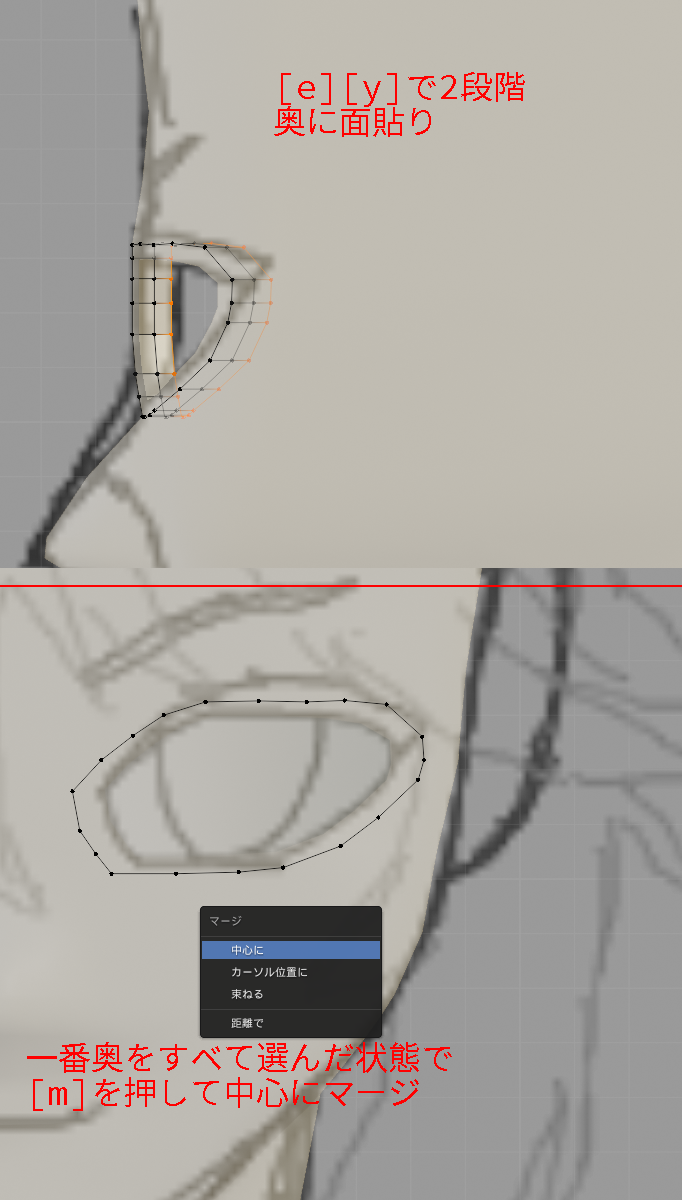
白目に色を付けておきます。
現在、顔と白目で同じマテリアルを使っているため、まずはマテリアルを分離します。
まずオブジェクトモードに戻り、右下のマテリアルのメニューから数字のボタンをクリックすれば分離されます。

ベースカラーを設定し、適当に名前を変えておきます。(ローマ字を使ってるのは私の好みで、日本語も使えます)

瞳を作る
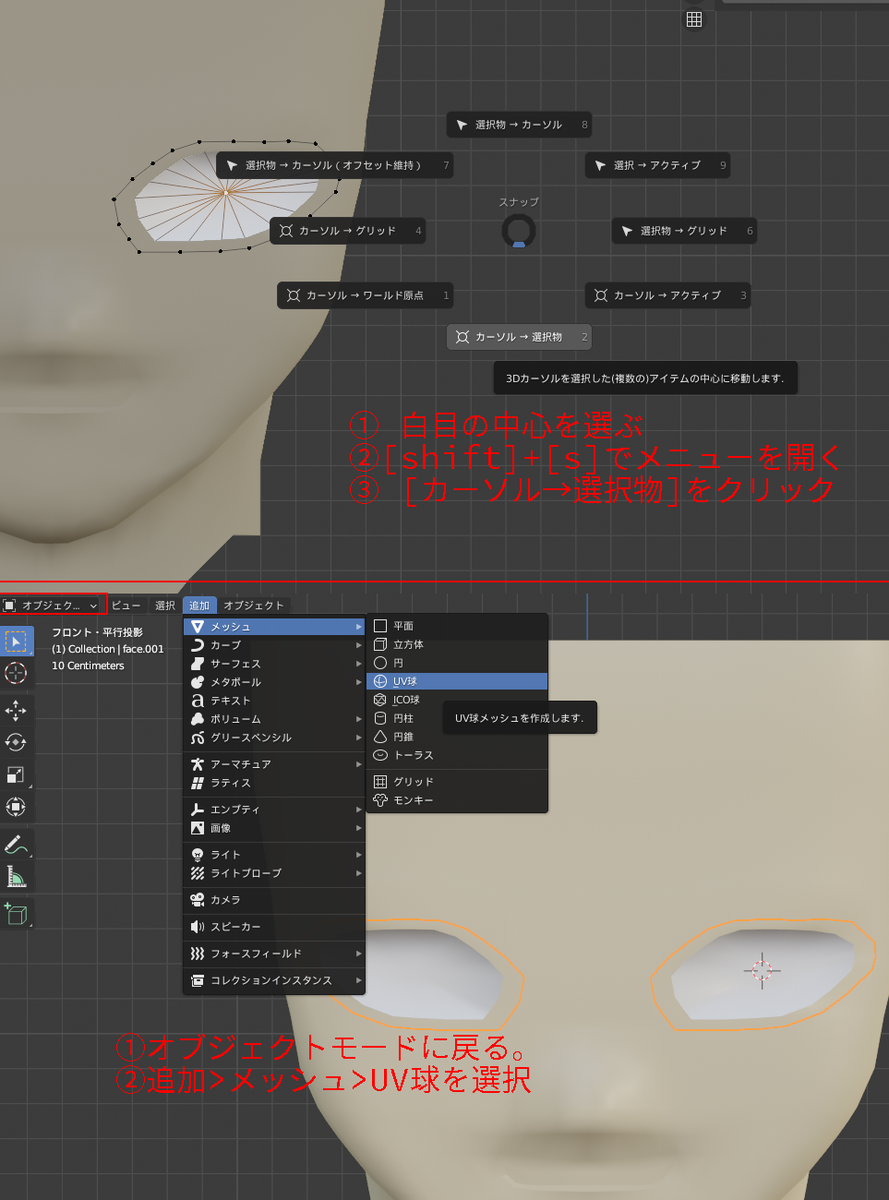
オブジェクトの追加では、3Dカーソルがある位置にオブジェクトが挿入されます。
そこで今回は、白目の中心にカーソルをあわせてオブジェクトを作成してみます。
白目のオブジェクトで編集モードに入り、中心の頂点を選択状態にします。
[shift]+[s]でメニューを開き、[カーソル]→[選択物]を選びます。
オブジェクトモードに戻り、[追加]>[メッシュ]>[UV球]を選びます。
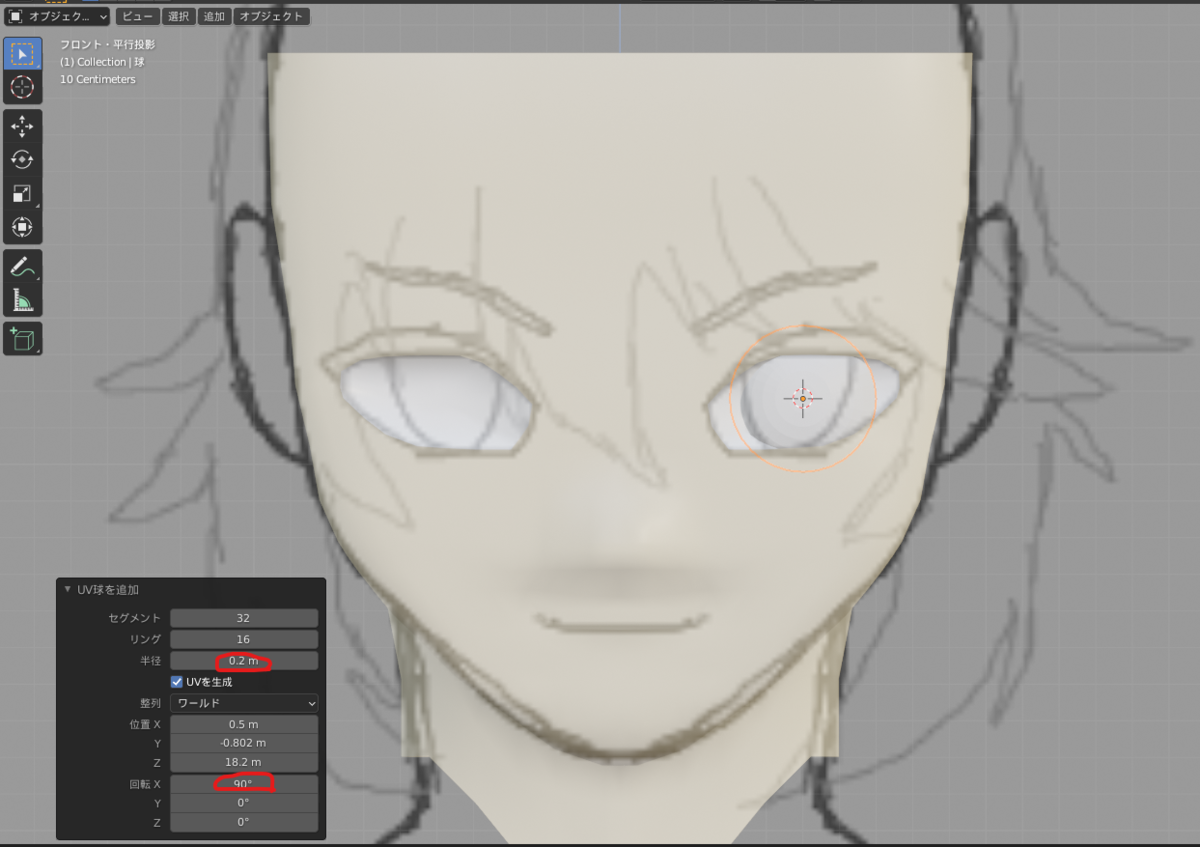
x軸方向に90度回転させ、半径を下絵の瞳の大きさにだいたいあうように調整します。
後ろ半分を削除します。

ピポットポイント(拡大縮小や回転の基準位置)をデフォルトの[中点]から[3Dカーソル]に切り替えます。
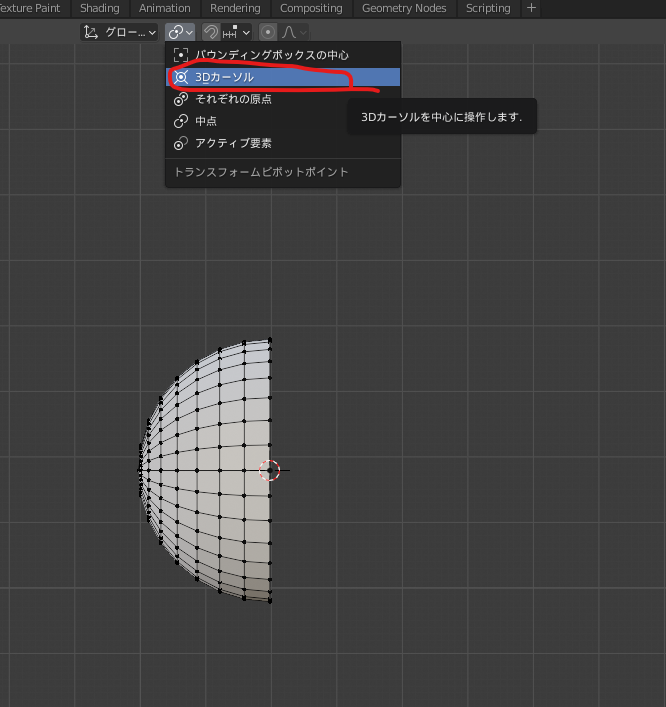
[s][y]を使って適当に縮めます。1番右のリングと、右から2番目のリングの距離が瞳の厚みになります。
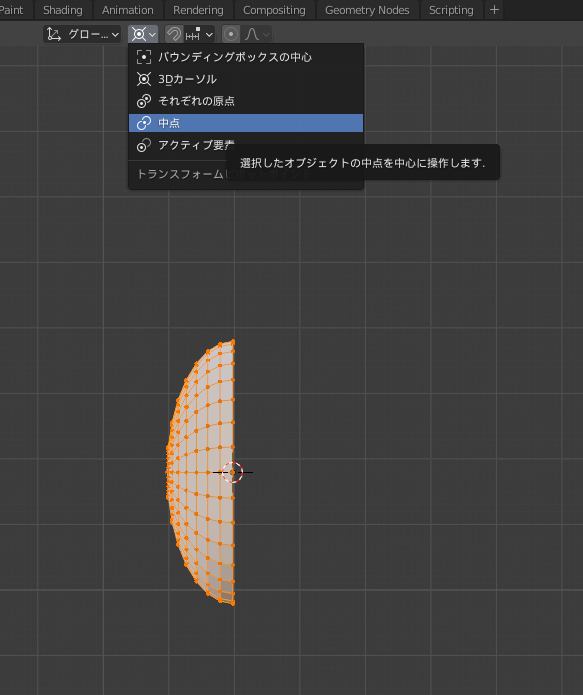
[alt]+クリックを使って、右から2番目のリングを選択し、[shift]+[s]で3dカーソルを移動させます。
[s][y]に続けて数字を入力することで、拡大縮小の倍率を指定できます。
一番右のリングを除いてすべてを選択し、[s][y][0]と入力して、選択頂点を3Dカーソルに揃えます。

プロポーショナル変形を有効にすると、移動・拡大縮小・回転をしたとき、選択した周りの頂点がいい感じに連動します。
外側から2つリングを選択し、[o]を押してプロポーショナル編集を有効にします。
[g][y]で移動モードに入ります。
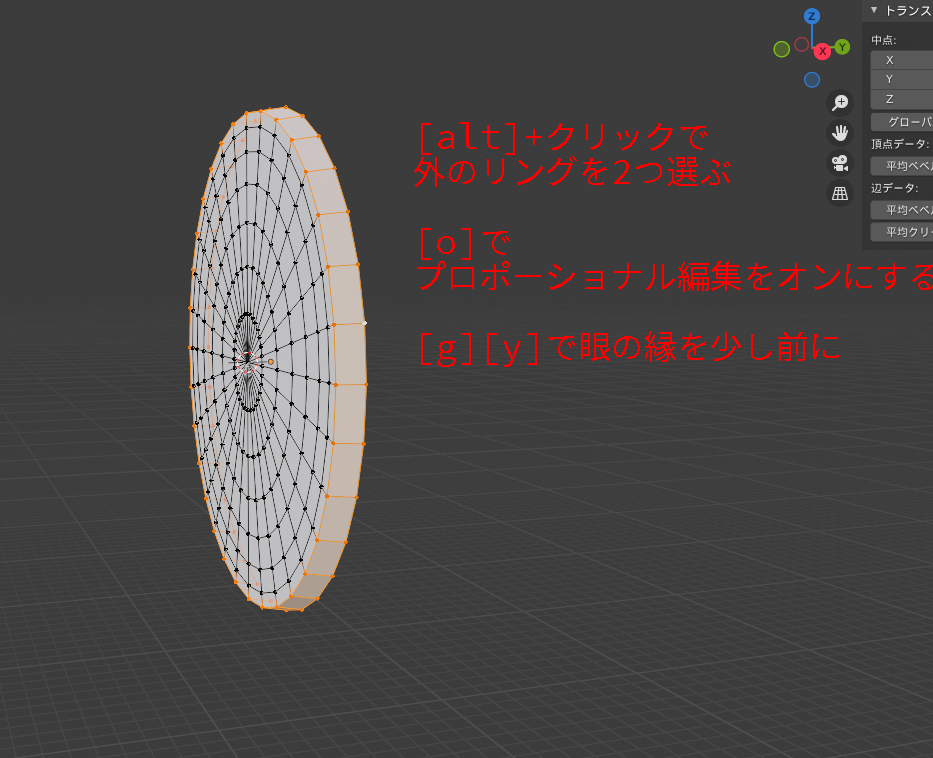
プロポーショナル変形モードでは、影響範囲がグレーの円で表示されます。
デフォルトでは大きすぎるのでホイールで調整します。
少しだけ縁が反るような形にします。

ラティスで瞳の形を整える。
ラティスを作ると、オブジェクトの形を直感的に変形させることができます。
まずオブジェクトモードに戻り、[追加]>[ラティス]を選択します。
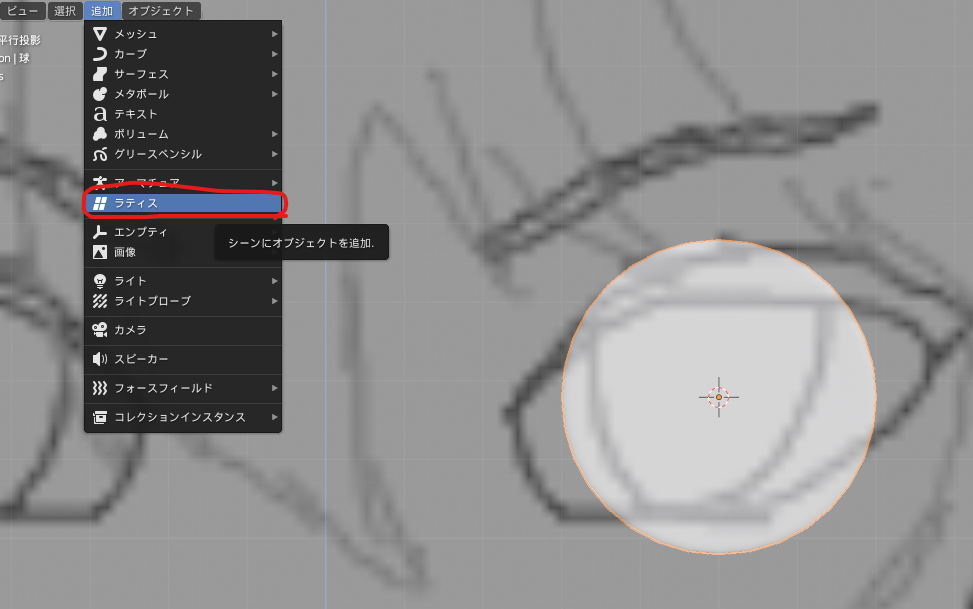
オブジェクトモードのまま、[g]や[s]を使って、ラティスを瞳の大きさより少し大きいぐらいにあわせます。
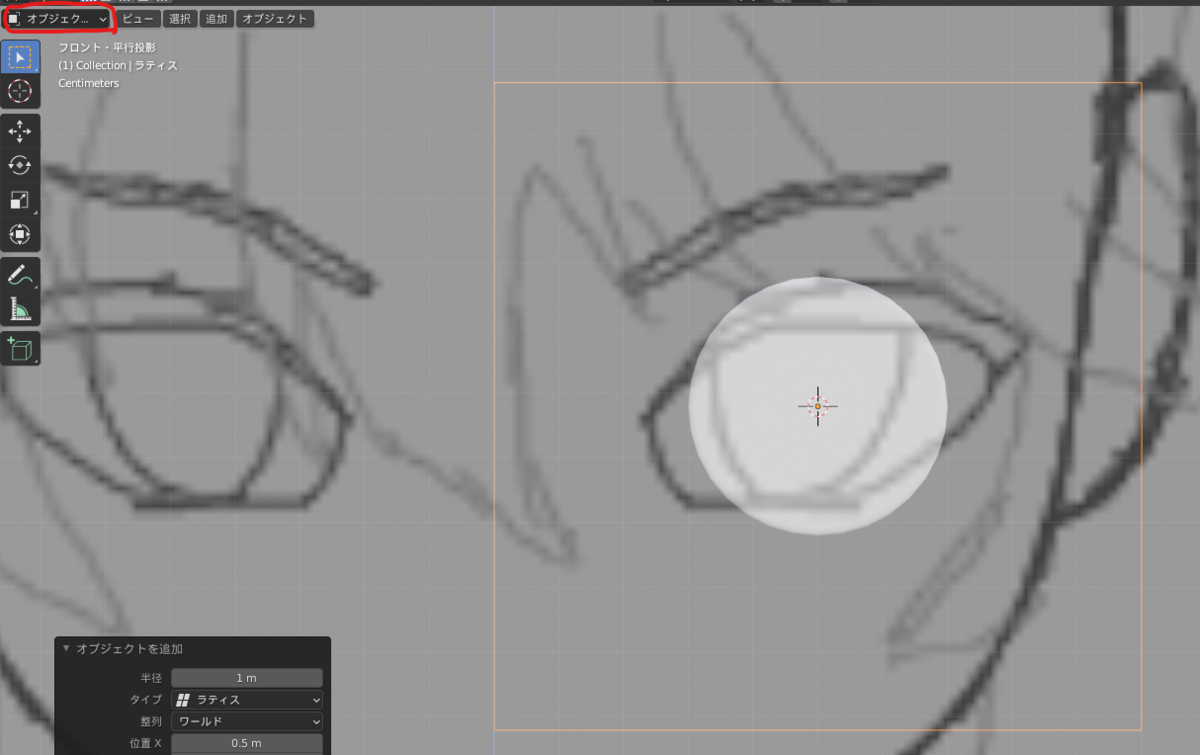
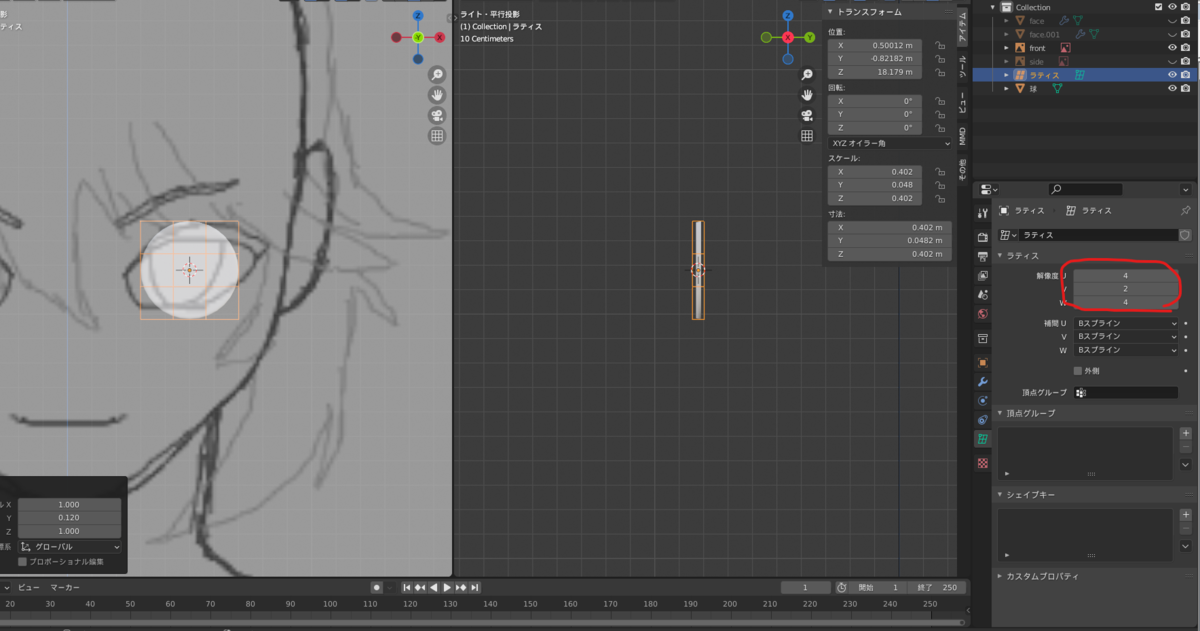
右下のメニューから、ラティスの解像度のUとWを適当に増やします。
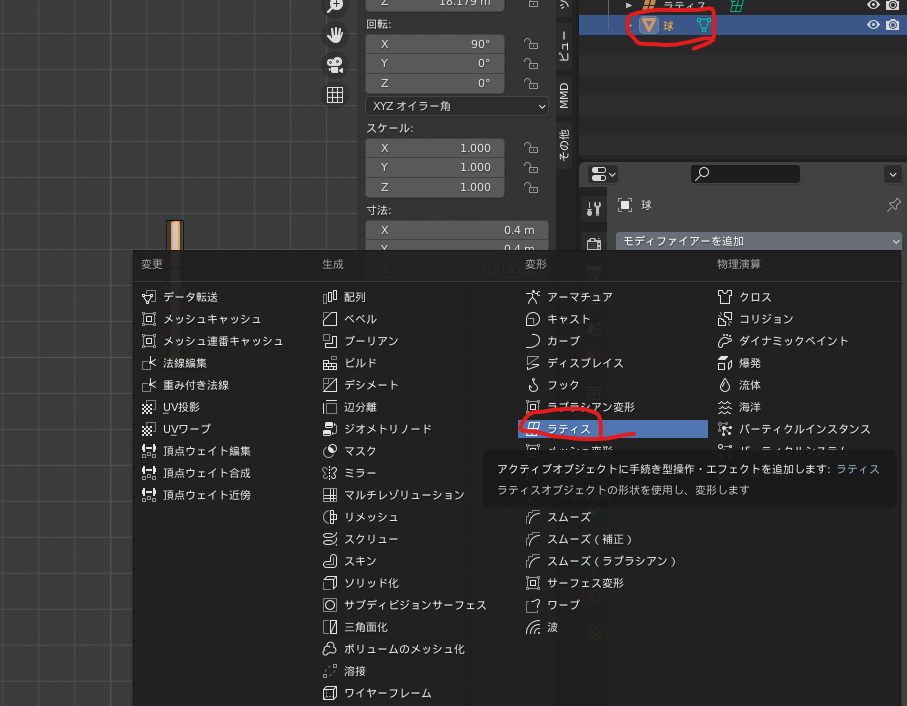
瞳のオブジェクトを選択し、モディファイアのメニューからラティスを選択します。
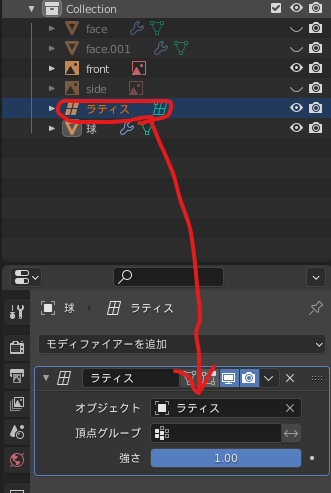
先ほど作成したラティスオブジェクトを、ラティスモディファイアにドラッグ&ドロップします。
ラティスオブジェクトを選択し、編集モードに入ります。
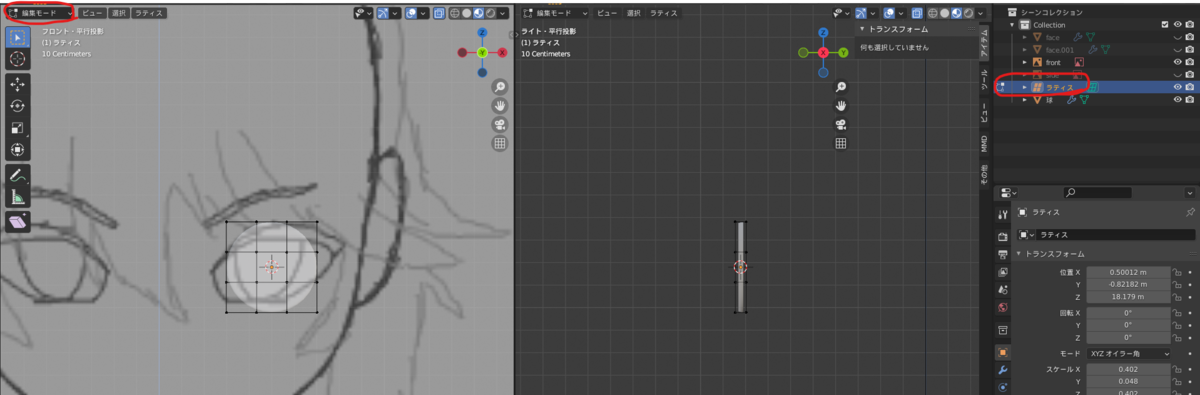
ラティスの頂点を動かすと、連動して瞳が変形します。これを使って下絵に形をあわせていきます。
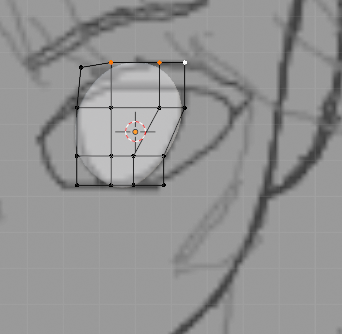
y軸方向もあわせます。 [a]や[b]で範囲選択し、[r]で回転させると楽です。
画像では適当に色を付けています。
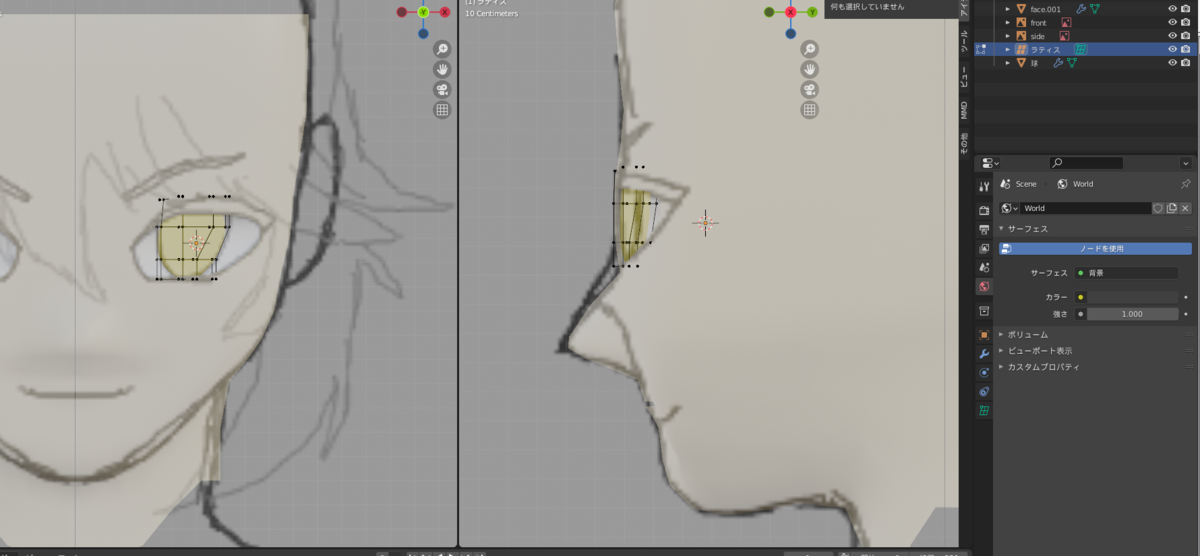
使い終わったらラティスを非表示にしておきます。
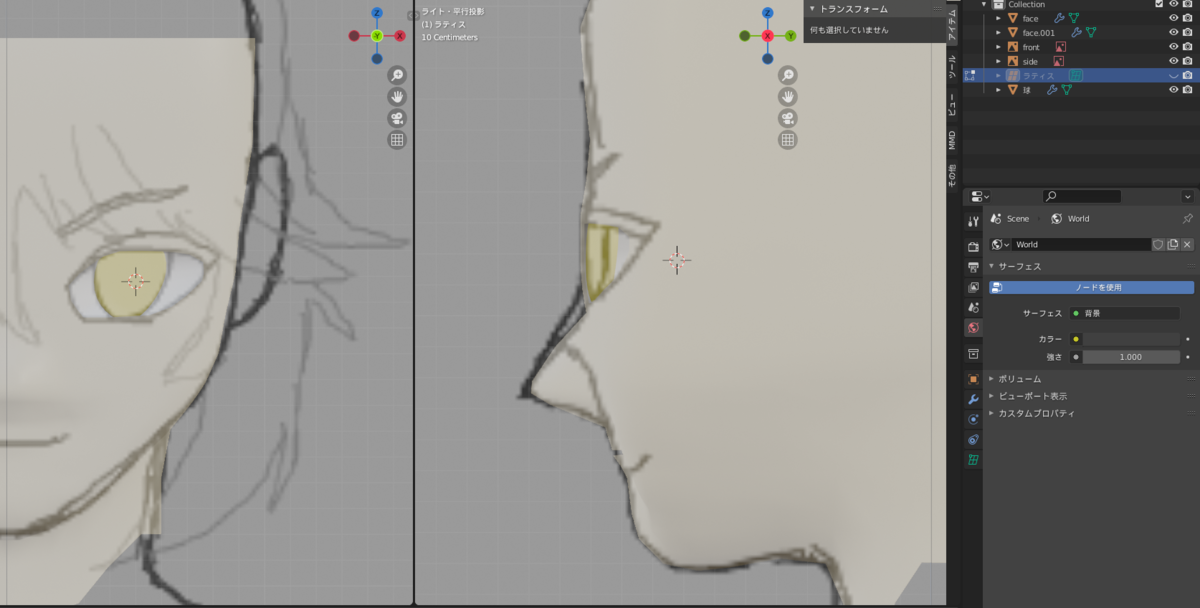
瞳にミラーモディファイアを設定する。
今回3Dカーソルを動かして、瞳のオブジェクトを生成したため、オブジェクトの原点がずれています。
ミラーモディファイアはオブジェクトの原点を基準にミラーを生成するため、このままでは使えません。
そこで3Dカーソルを原点に移動させてから、ミラーモディファイアを設定します。
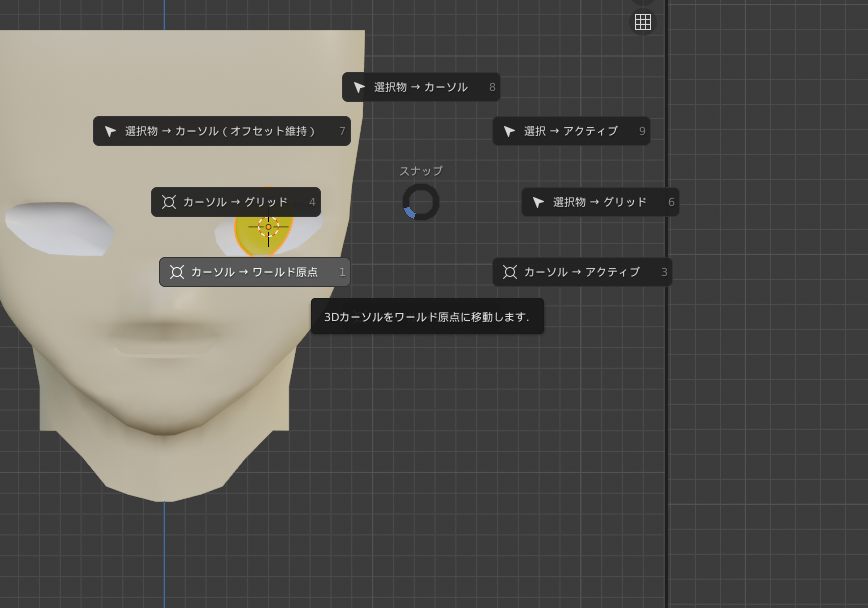
[shift]+[s]メニューから[カーソル → ワールド原点]を選ぶ
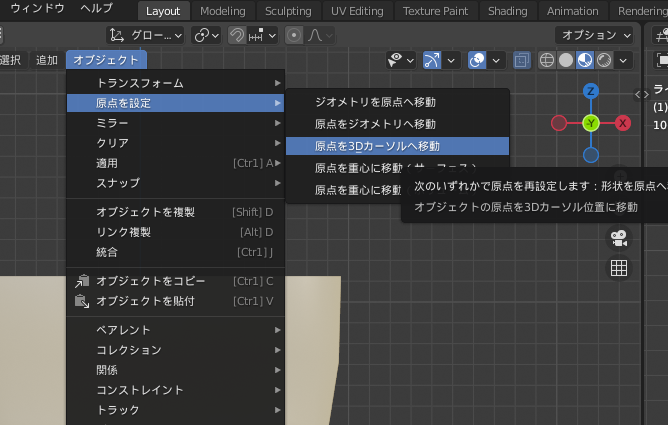
[オブジェクト]>[原点を設定]>[原点を3Dカーソルへ移動]を選ぶ
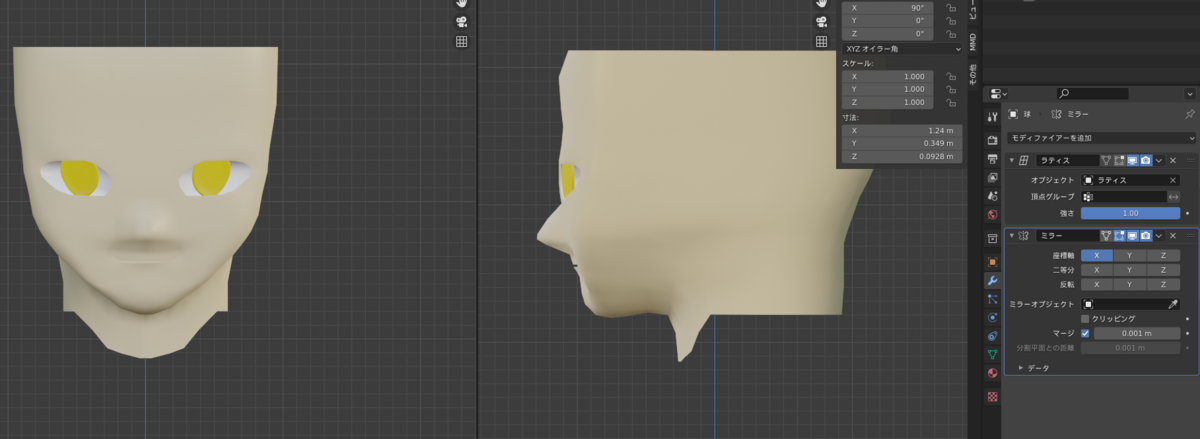
ミラーモディファイアを設定して完了です。
UTAUユーザーのためのblenderでMMDモデル作る(8.顔を作る4_後頭部)
目次
この記事でやること
- 後頭部を作る
- 暫定で色を付ける
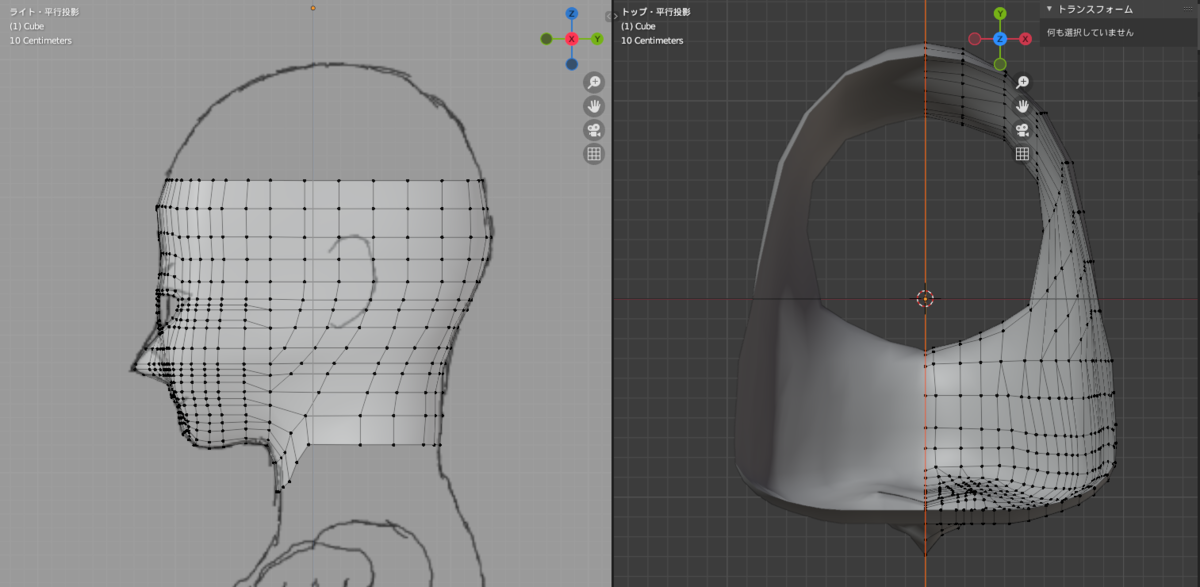
後頭部を作る
今回の方針として、髪の毛で見えない部分は作りません。
耳のあたりの辺を[e][y]の面貼りで後頭部あたりまで伸ばします。
伸ばした頂点を[g][x]でミラーが吸い付くところまで移動します。
[ctrl]+[r]でループカットして、[g]で形を整えます。

- [e][z]と[m]を使って上側を作りました。
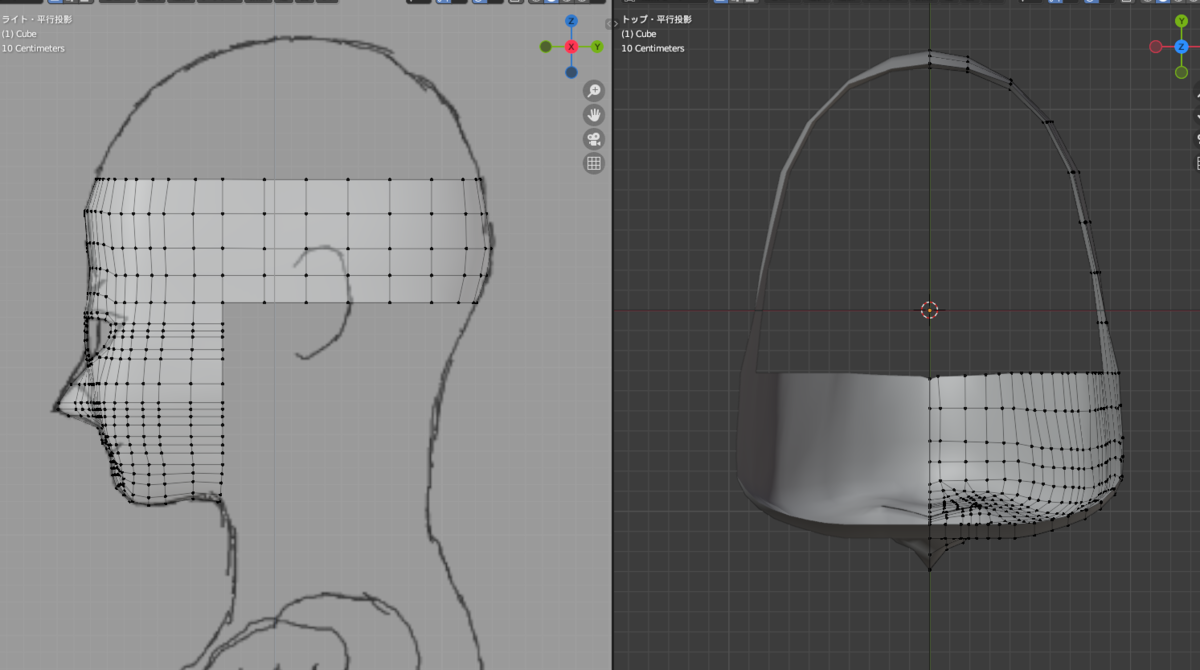
下側も同様に首の上端あたりまで作ります。
暫定で色を付ける。
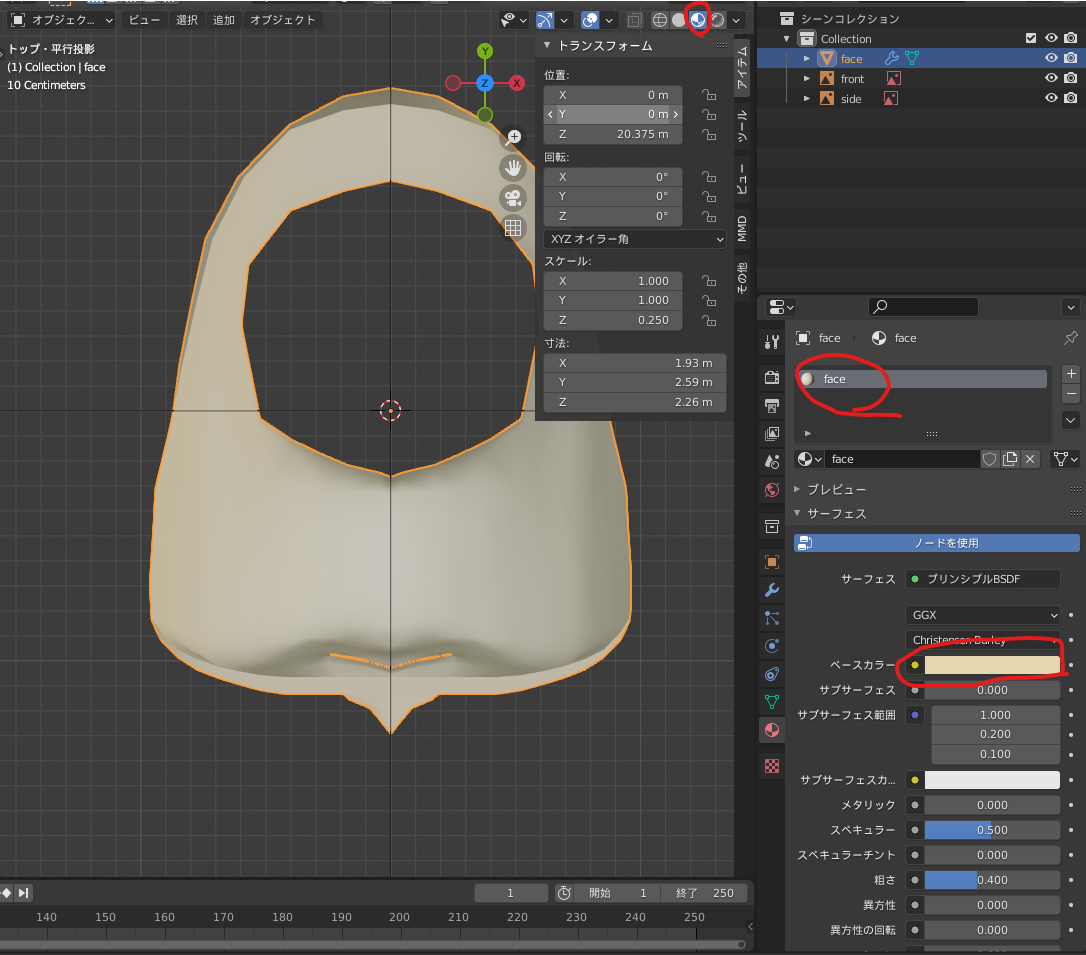
真面目な設定はMMD用の設定が必要なので、終盤でやりますが、とりあえず色が付いたほうが雰囲気がつかみやすいので、仮に色を置いていきます。
右下のメニューからマテリアルの画面に入ります。
デフォルトでベースカラーを適当に肌色っぽくし、マテリアルの名称をわかりやすいものに変えておきます。
UTAUユーザーのためのblenderでMMDモデル作る(7.顔を作る3_前面)
目次
この記事でやること
- フィル[f]
- ナイフ[k]
- マージ[m]
フィルとナイフで間を埋める
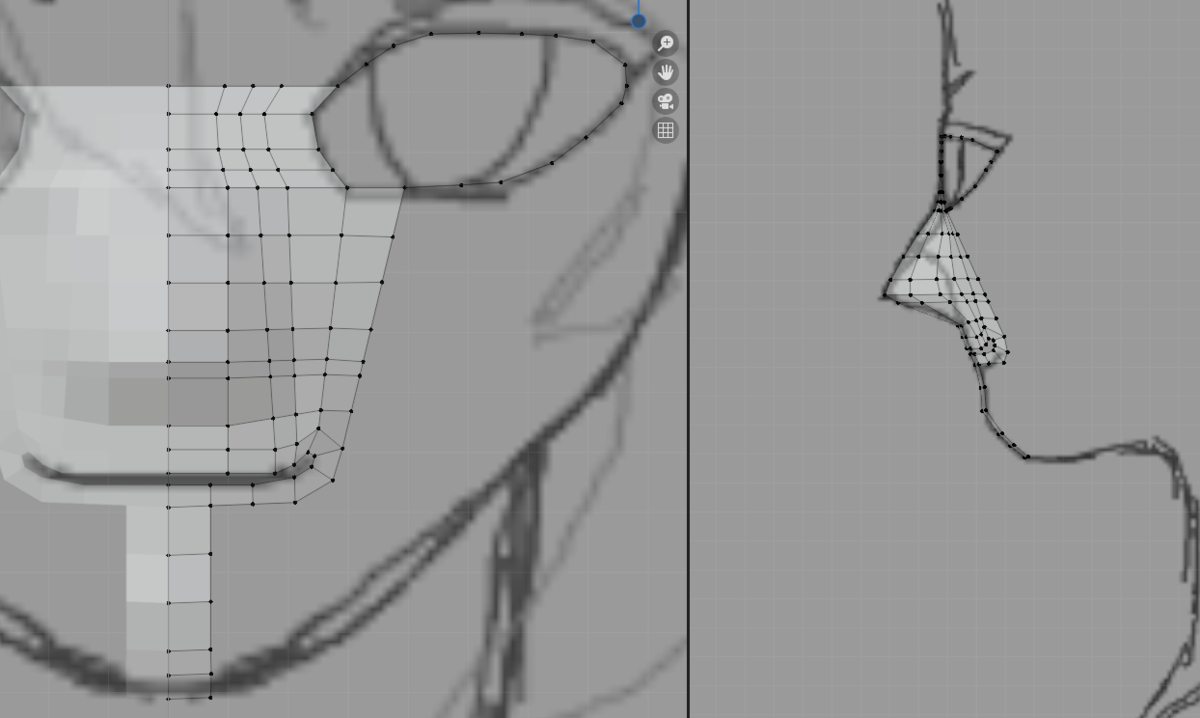
目の左下の辺、鼻筋の右の辺、唇の左上の辺を選択します。
[ctrl]を押しながらクリックが便利です。
[f]を押すと、選択しているすべての頂点を含む面が生成されました。
今回作成した面は四角形ではないので、ループカットはできません。
[k]のナイフを使って左の頂点にあわせて右の辺を分割していきます。

同様の手順を繰り返し、目と唇をすべて埋めました。
画像で解説はしませんが、適宜テンキーの[3]で側面に切替、y軸方向の位置も下絵にあわせて修正していきます。
同様に顎と唇の間も埋めました。

面貼りとマージで頬を作っていく
目の下あたりから唇までの右辺を選択し、[e][x]で右に面貼りします。
面貼りで作った右上の頂点と、眼の縁の頂点を同時に選択し、[m]でマージメニューを開きます。
[中心に]や[最初に選択した頂点に]などを使って、頂点を結合します。

どんどん面貼りして顔の全面を仕上げる。
新しい操作方法はありません。[e][g]などでどんどん面貼りしていきます。
上半分を作った様子です。
[3]だけでは、頬のラインはわかりにくいので、適宜[ctrl]+テンキーの[7]などを使って下からの目線にします。
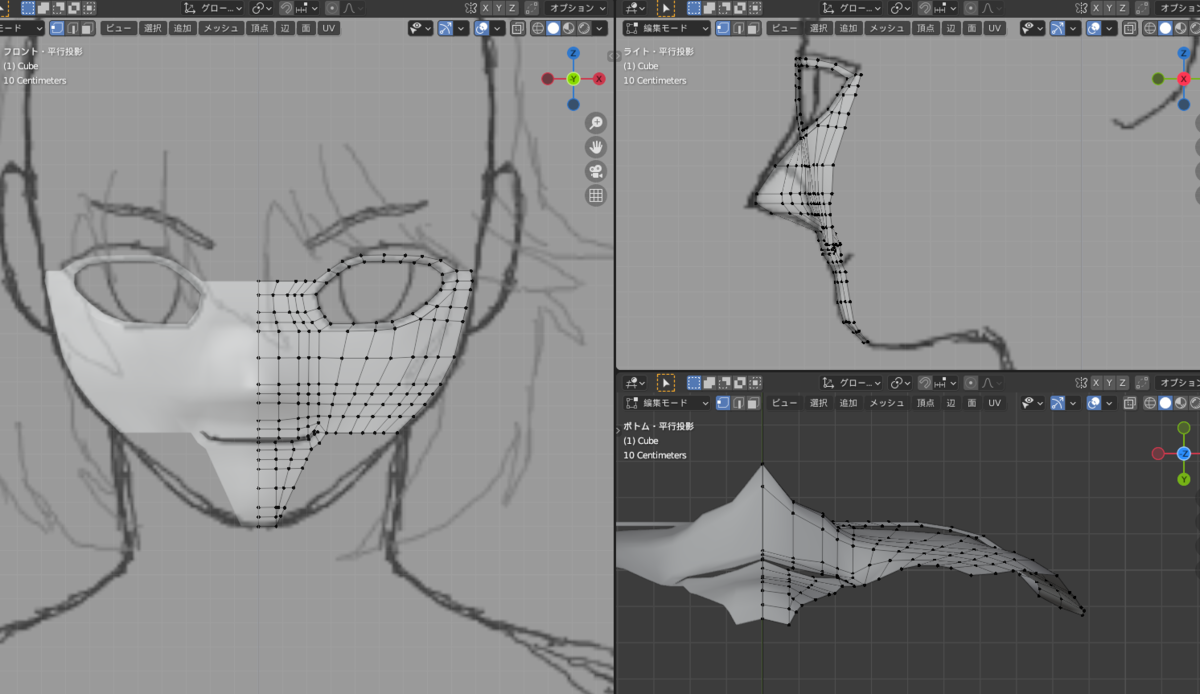
顔の下側は処理を決めかねたのでとりあえず1段だけ増やしました。
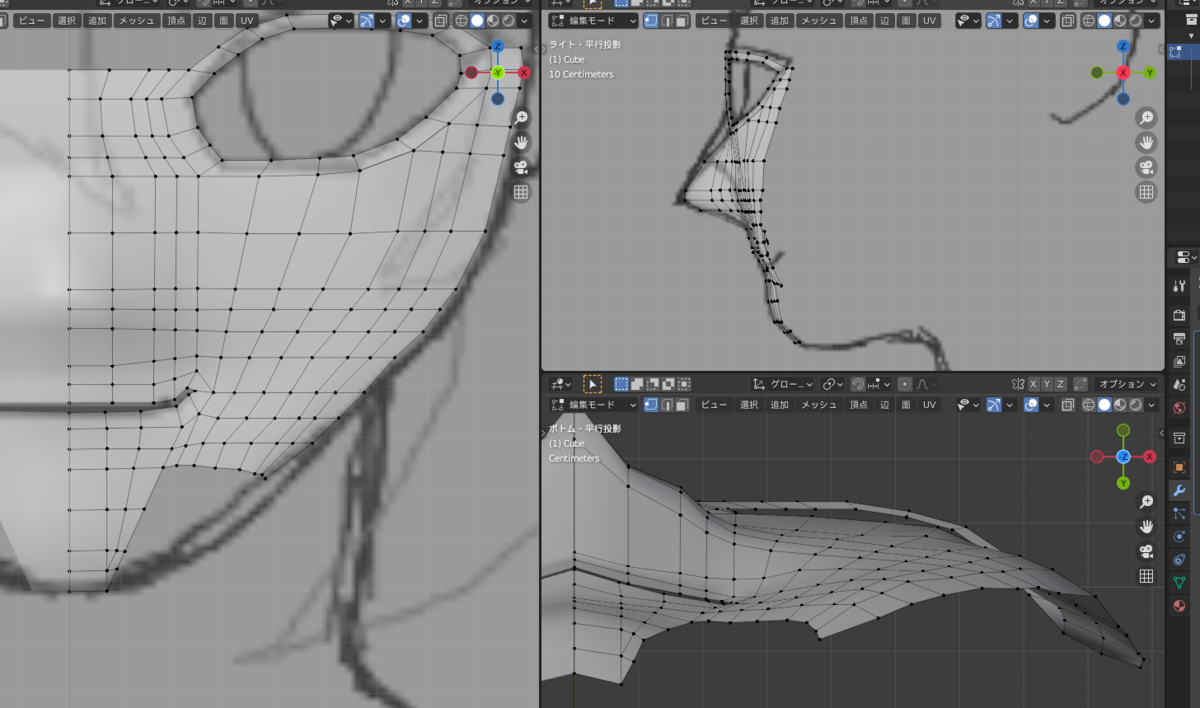
先に側面を伸ばしていきます。[3]と[ctrl]+[7]の画面が見やすいです。

とりあえず全部埋めました。
顎のあたりが汚いですが、最悪目の周りと口の周りが綺麗にできていればなんとかんります。
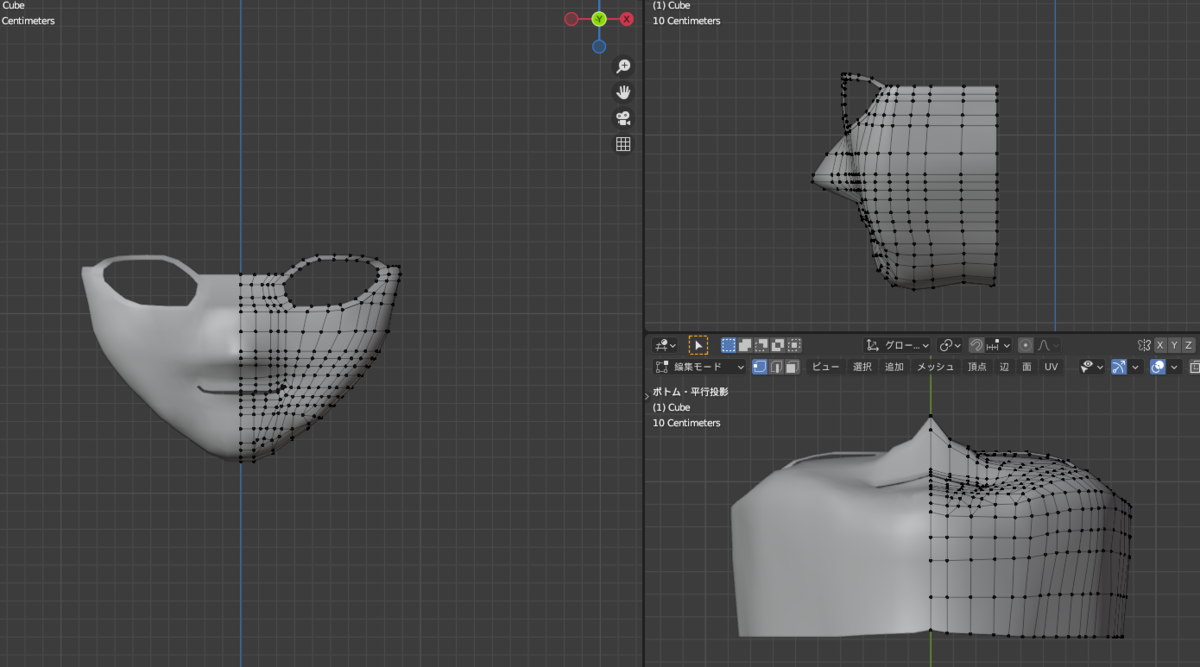
全体を微調整しました。

UTAUユーザーのためのblenderでMMDモデル作る(6.顔を作る2_鼻・口)
目次
この記事でやること
- 拡大縮小[s]
- 面貼り[e]
- ループカット[ctrl]+[r]
- シェーディングの切替
前回作成した眼の縁を使って、最初の面を張る
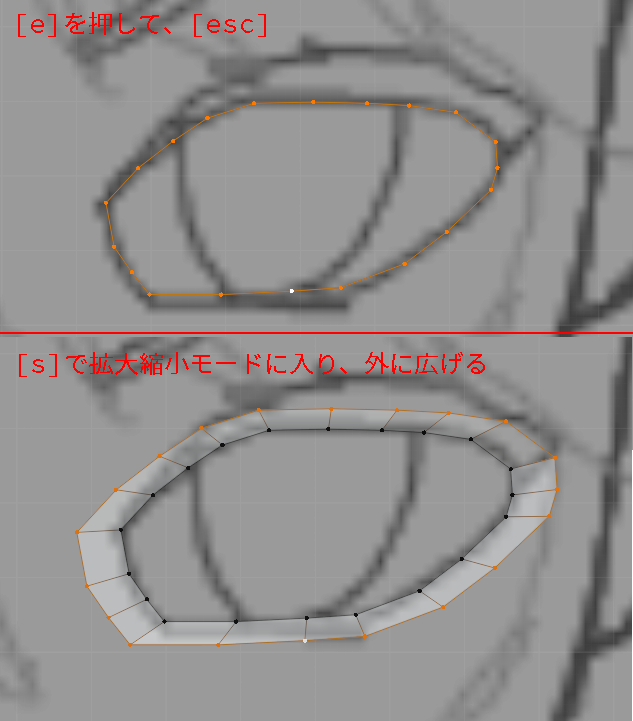
- まず前回作成した頂点を[a]ですべて選びます。
次に[e]を押します。これで面が作成されました。
このままでは作成された面を綺麗に操作するのが難しいため、一度[esc]を押して操作を確定します。
今作成した面が選択された状態で[s]を押し、拡大縮小モードに入ります。
マウスを動かすと、選択した頂点の中心を基準に拡大縮小されますので、画像のように広げます。
面貼りで鼻筋を作る
(解説画像が、1つ前のステップ飛ばしてしまっています。手順は変わらないので無視してください。)
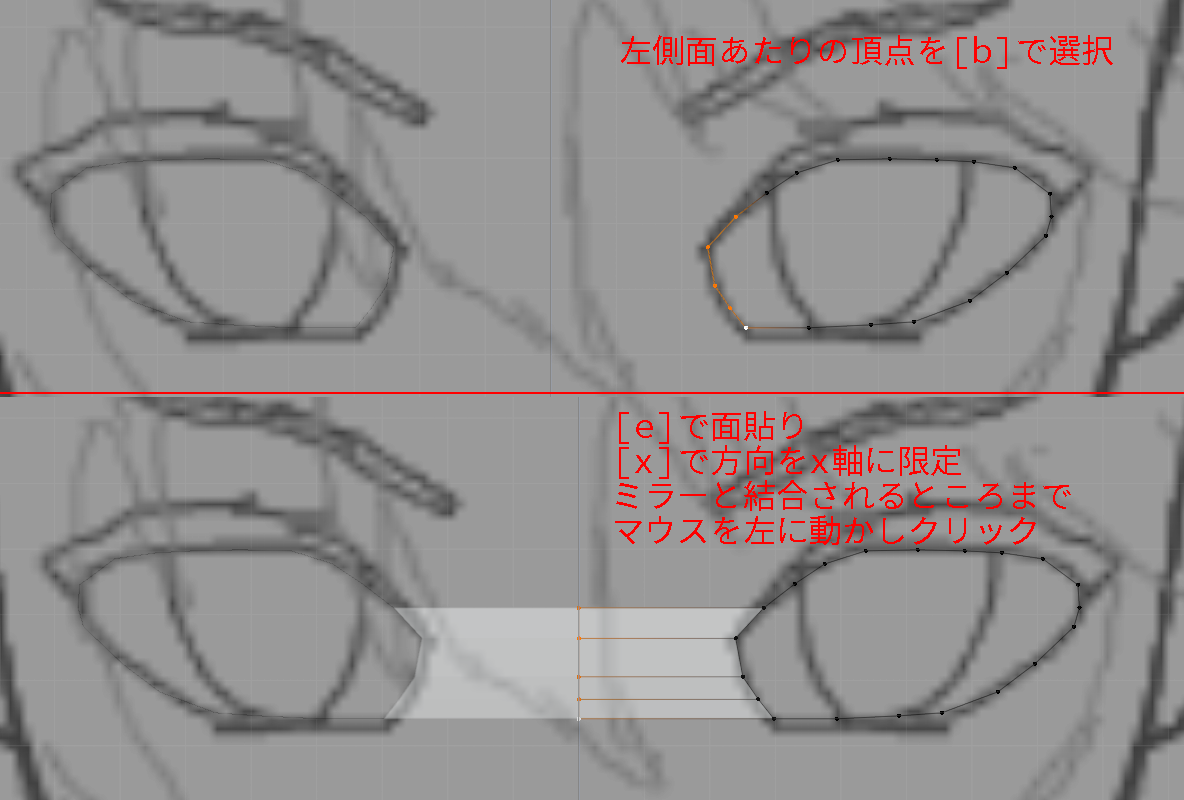
- 目の左側の頂点をすべて選びます。
- [e]で面貼りモードに入り[x]を押して、移動できる方向をx軸に限定させます。
マウスを左に移動させて、ミラーと吸い付くところまで移動させます。
テンキーの[3]を押して視点を側面にし、作成した頂点を[g][y]で鼻筋にあわせていきます。

このままでは目の左側の面が大きいので、ループカットで分割していきます。
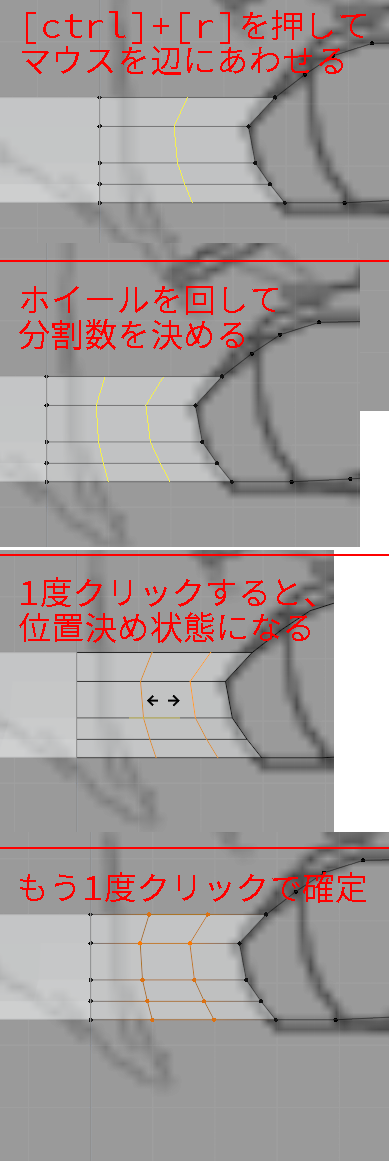
[ctrl] + [r]をクリックして、分割したい辺にカーソルをあわせます。
マウスホイールを動かして、分割数を決めます。3分割ぐらいでしょうか?
クリックを2度押して確定します。
1回目のクリックが分割数の確定、2回目のクリックが分割位置の確定です。
このまま鼻筋を作っていきます。
分割した一番左の面を[b]で選択し、[e]で面貼り、[z]で方向をz軸に固定します。
下絵の口のラインあたりまで、面を張ります。
[ctrl]+[r]のループカットで適当に分割します。
テンキーの[3]で横からの視点になり、鼻筋を整えます。
あとで全体のバランスを見ながら修正するので、あまり神経質にならなくて大丈夫です。

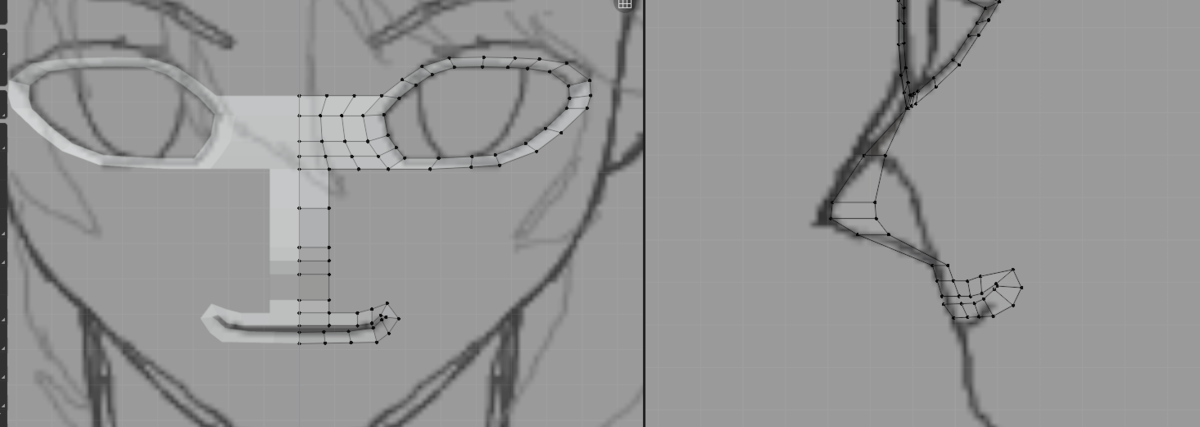
ここまでの成果はこんな感じ

面貼りで唇を作る
[ctrl]+[r]のループカットを使って、作成したポリゴンの一番下を、唇の厚みぐらいにします。
[e][x]で右方向に2回面貼りし、[g][x]や[g][z]を使って、上唇の形に添わせていきます。
同様に[e]や[g]と[x][y][z]を組み合わせて、唇を作成します。

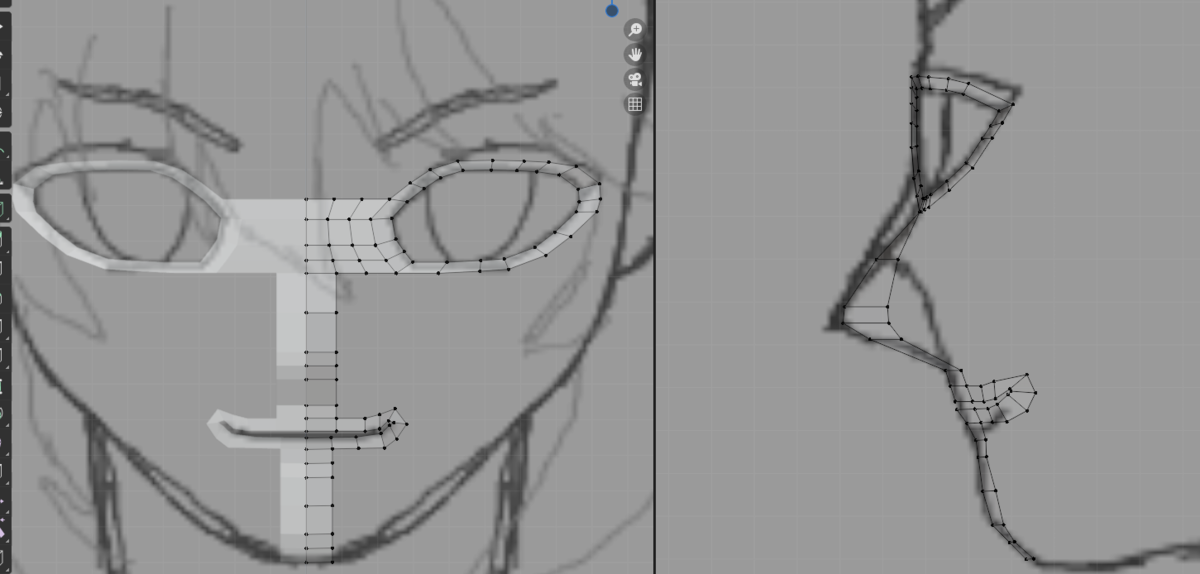
ここまでの成果はこんな感じ
顔の中心のラインを顎まで
同様に[e]と[g]を使って、顔の中心のラインを仕上げました。
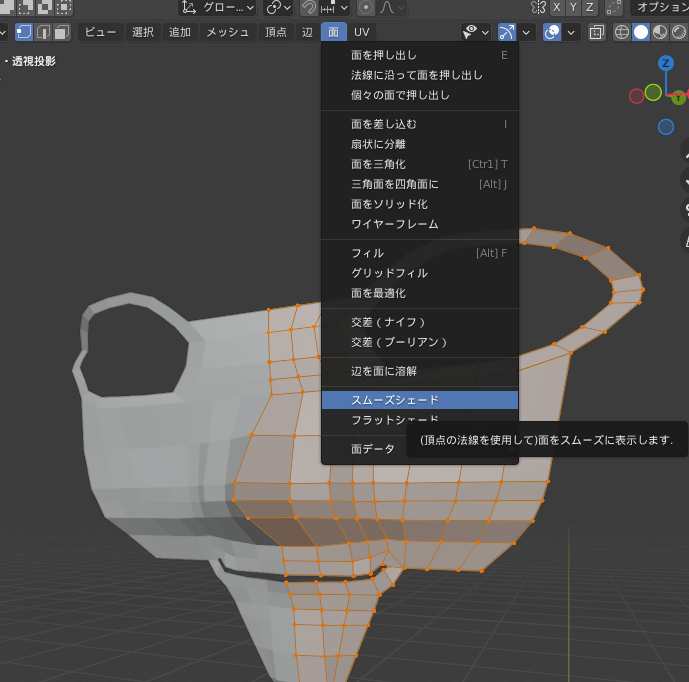
シェーディングをスムーズシェードに切り替える
ここまで作ってきているものは、いかにも一昔前のCGですという感じのカクカクした仕上がりになっていると思います。
これはデフォルトでは「フラットシェード」というモードだからです。
これを「スムーズシェード」に切り替えると、面のなす角度が一定以下ならば、滑らかな曲面で表示されるようになります。
[a]ですべてを選択し、[面]→[スムーズシェード]を選択します。
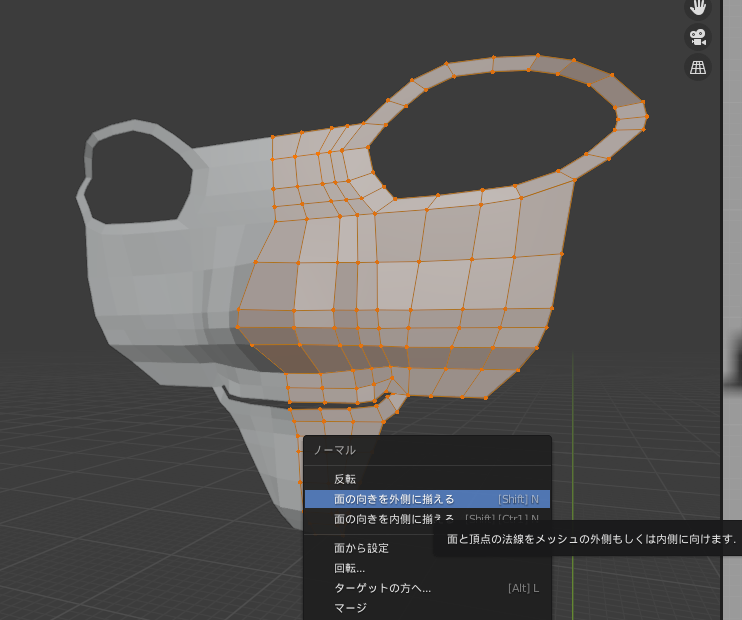
綺麗にならないときは、面が裏向きの可能性があります(面には裏表があります。)
右上のメニューから、[面の向き]にチェックを付けると、表面が青、裏面が赤で表示されます。

正面からみてすべてが青ならOKです。
赤が混じっていたら、[a]や[b]で裏返っている箇所を選択し、[alt]+[n]でノーマルメニューを開いて、[面の向きを外側にそろえる]を押します。
UTAUユーザーのためのblenderでMMDモデル作る(5.顔を作る1_目の縁)
目次
この記事でやること
- 眼の縁を作成する。
- オブジェクトモードと編集モードの切替
- 全選択[a]、範囲選択[b]
- 削除[x]
- 移動[g]
- ミラーモディファイア
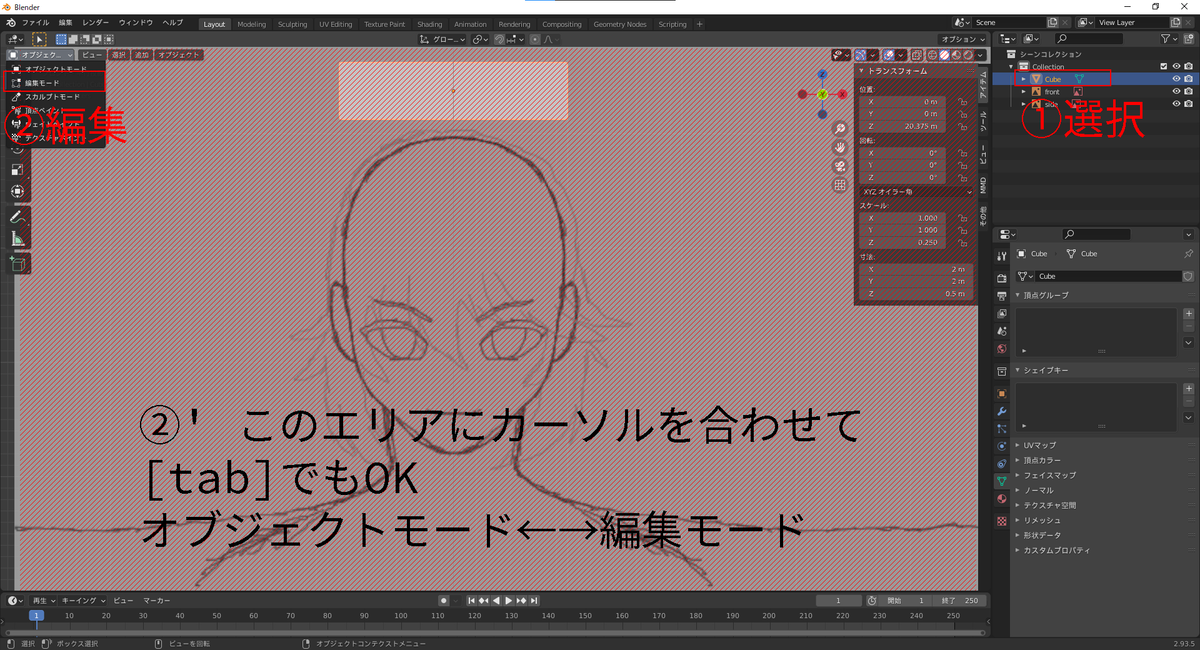
オブジェクトモードと編集モードの切替
blenderには複数のモードがあり、各モード毎にできることが異なります。
今回の記事は基本的に編集モードで進めていきます。
編集モードでは頂点を1つずつ操作することができます。
オブジェクトモードと編集モードの切り替えは、左上のメニューから操作できます。
また、編集エリアにマウスカーソルを合わせた状態で[tab]を押せば切り替わります。
眼の縁の作成
[シーンコレクション]からcubeを選択し、編集モードに入ります。
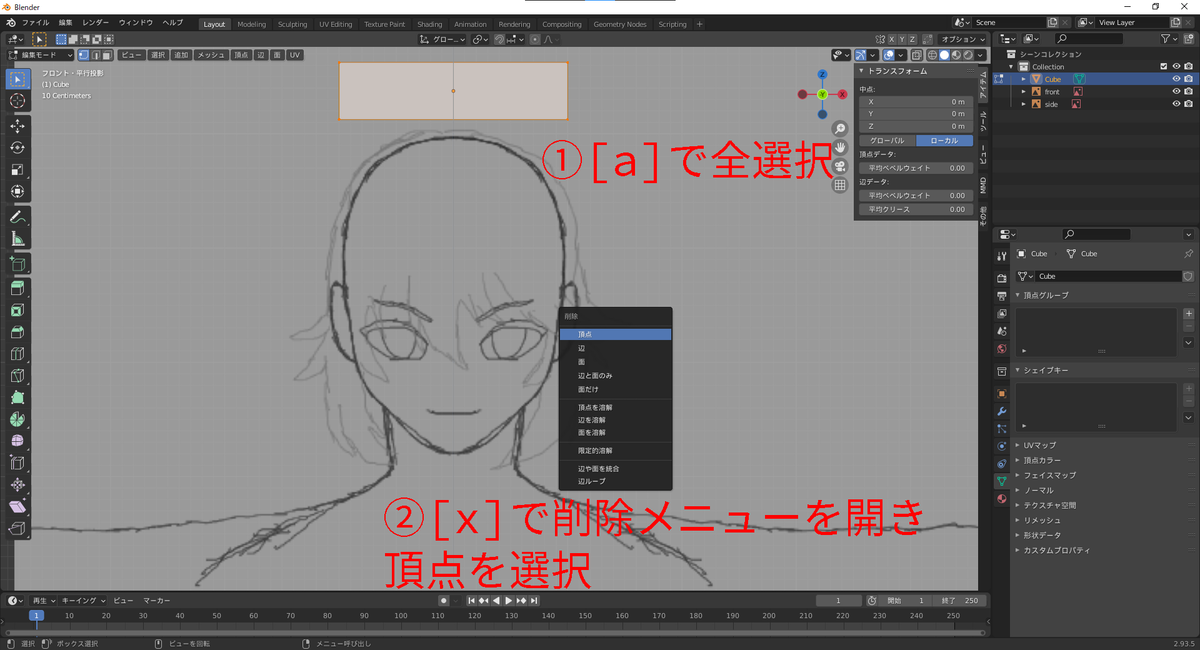
身長の目安に使った箱はもういらないので削除します。
- [a]で全選択し、[x]で削除メニューを開きます。
- 頂点を選択すればすべて消えます。
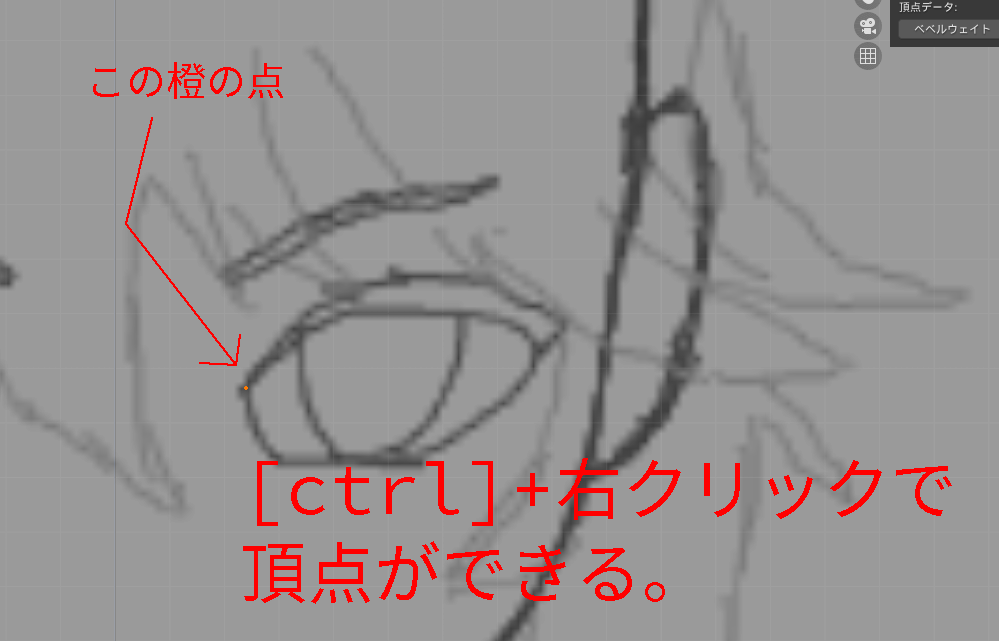
正面図の下絵に合わせて縁を作っていきます。
[ctrl]+右クリックで、頂点が作れます。
[ctrl]+右クリックを繰り返して、ぐるりと縁を作成します。

最初の頂点と最後の頂点を選択状態にします。
[ctrl]を押しながら頂点を選ぶか、[b]を押した後ドラッグで範囲選択ができます。

[f]を押すと、選択している頂点が繋がります。

作成した頂点を側面図にあわせていきます。
テンキーの[3]を押して側面を見ます。
作成された頂点は耳の前あたりで、目と位置があっていないことがわかります。
[a]を押してすべて選択します。
[g]を押すと、マウスで移動できるようになります。
さらにこの状態で、[x][y][z]のいずれかを押すと、その軸の方向のみに移動するようになります。
今回はy軸方向の編集をするので、[g][y]と続けて推します。
マウスで大体目のあたりにあわせてクリックします。

[1]を押して視点を正面に戻し、右側の頂点を1つ選択します。
[3]で視点を側面にし、[g][y]で位置をあわせます。
これを繰り返して、すべての頂点を側面図にあわせに行きます。

最終形はこんな感じです。
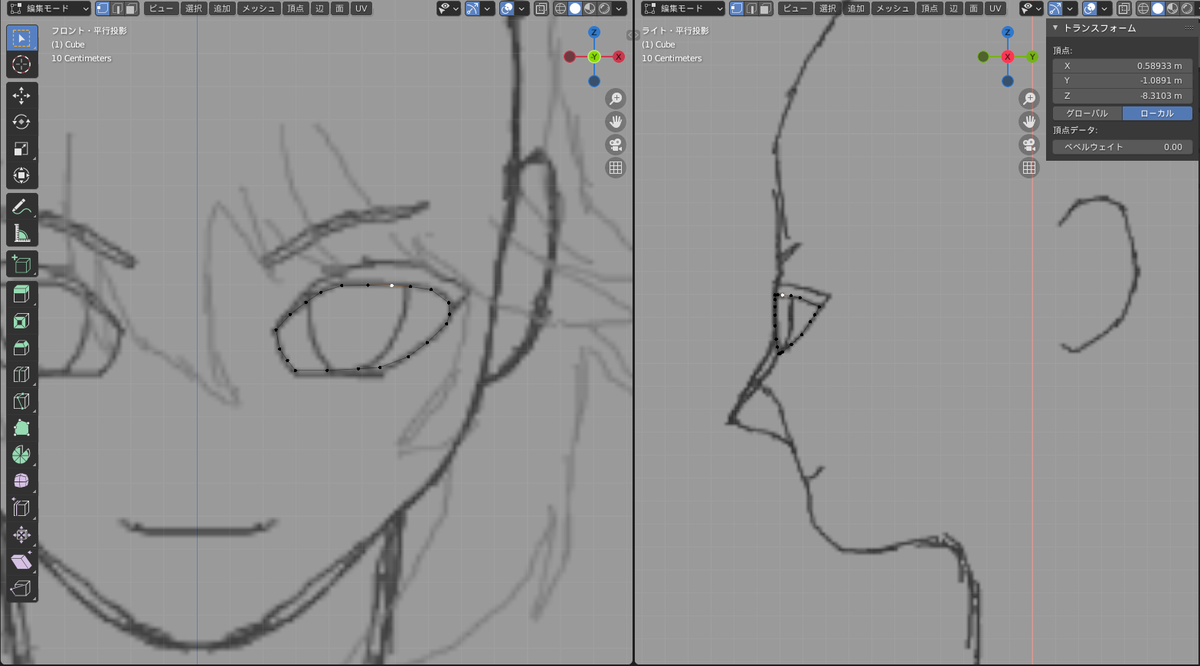
途中で分割数が足りなくてうまく頂点をあわせられないときは、2つの頂点を選択し右クリックで細分化します。
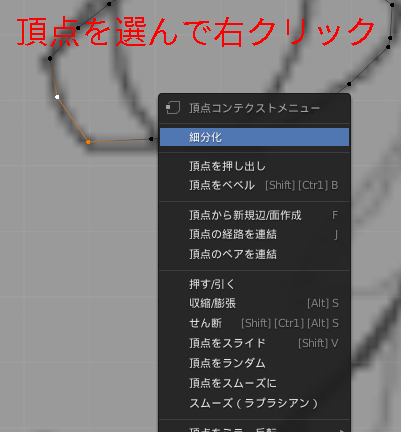
逆に頂点を分割しすぎた時は、[x]の削除メニューから[頂点を溶解]します。
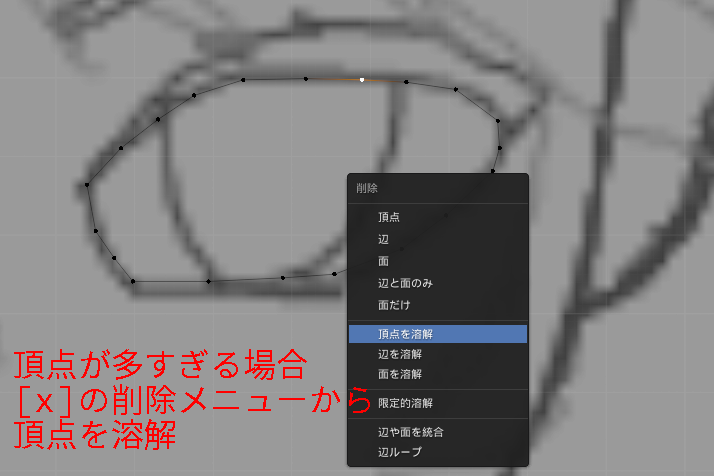
[g][g]と続けて押すと、頂点が直線上を動きます。

右下のメニューからモディファイアを設定します。
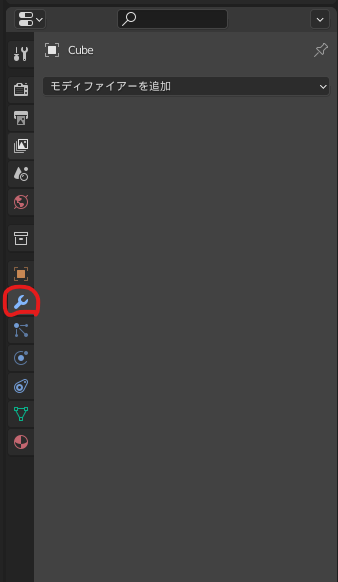
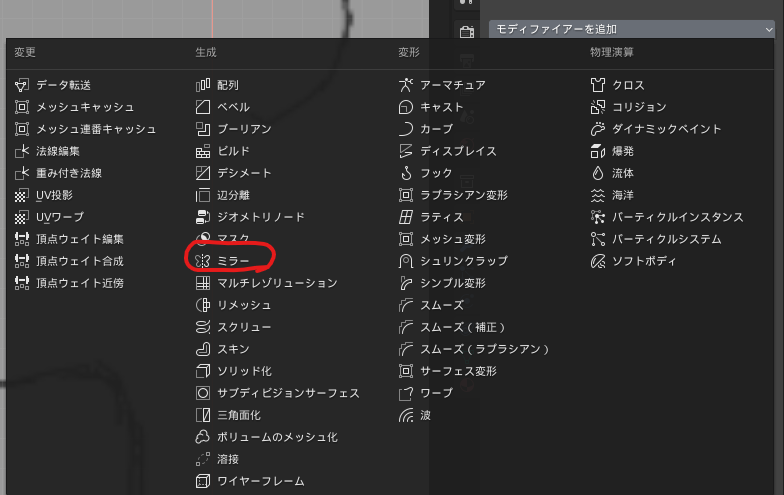
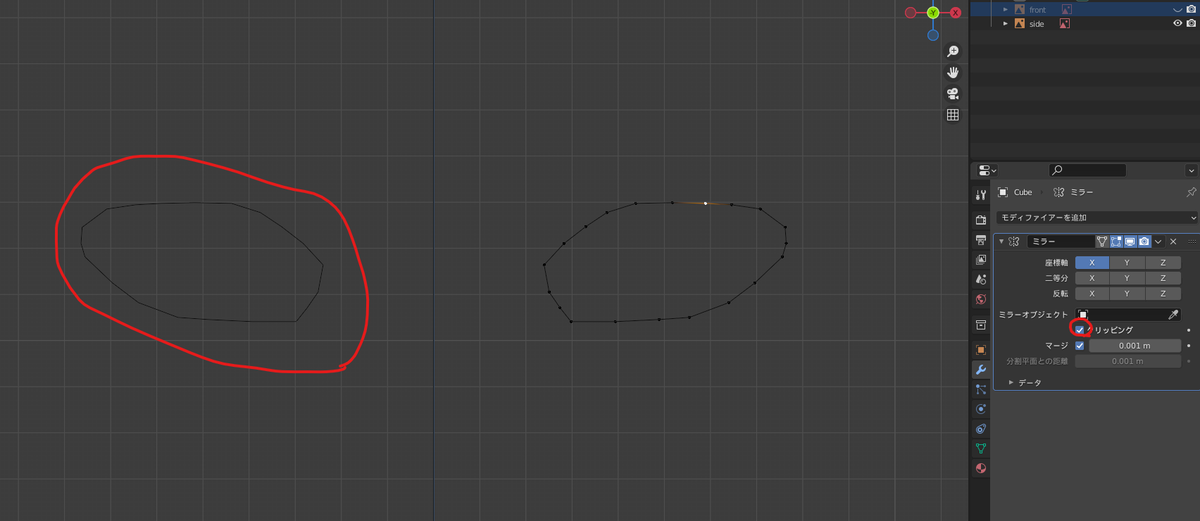
ミラーが正しく表示されないときは?
オブジェクトモードで移動をすると、ミラーの基準位置である原点までずれます。
- オブジェクトモードにします。
[shift]+[s]でメニューを開き、[カーソル→ワールド原点]を選びます。
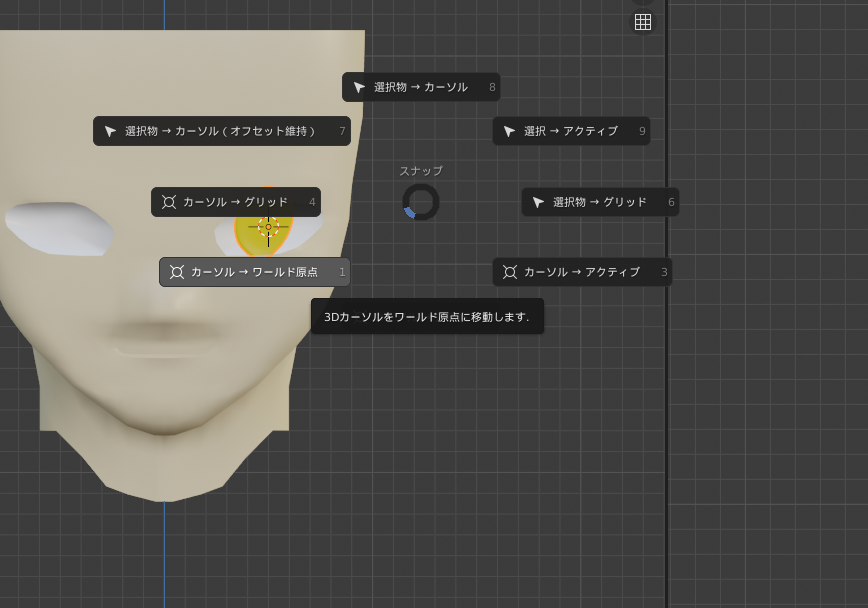
[オブジェクト]>[原点を設定]>[原点を3Dカーソルへ移動] これで治るはずです。
